【注意:多图,难以加载建议科学上网,或查看知乎的镜像文章: https://zhuanlan.zhihu.com/p/596739480 】
https://www.bilibili.com/video/BV1hD4y1k7Ty/
感谢原视频作者,华为昇腾架构师ZOMI酱(我愿称之为肝帝!)的超级贡献,有个视频提到了他录制的时候是凌晨一点(还有其他的休息时间)
可以看出他是真正热爱深度学习编译器、AI框架相关工作的,向他学习/致敬!绝对值得一键三连
第二节-为什么都用计算图

2.1神经网络框架遇到的问题
首要的问题是我们能够如何定义神经网络
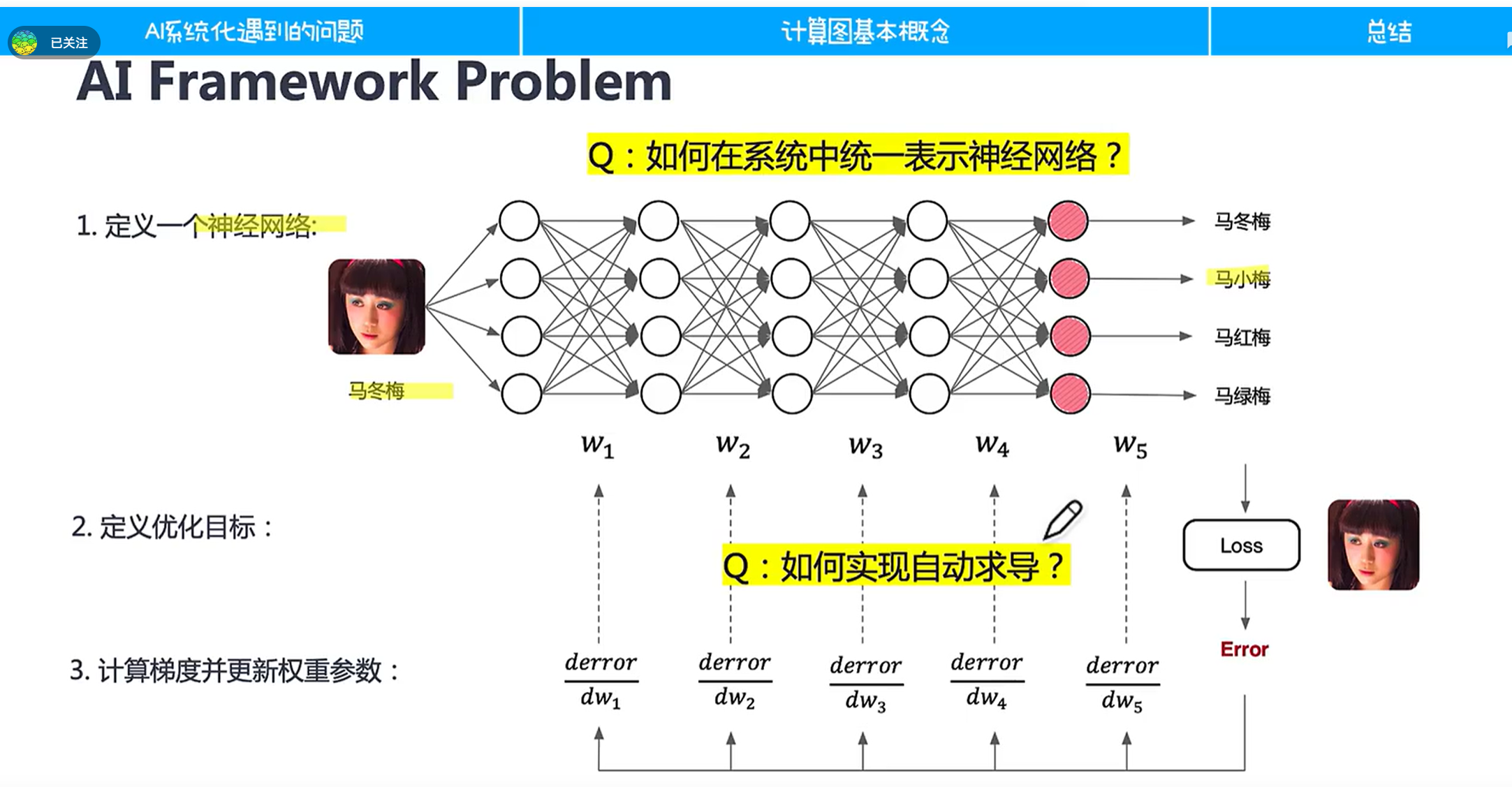
除了程序表示的问题,还要研究怎么让我们的表示在硬件框架能够高效执行。
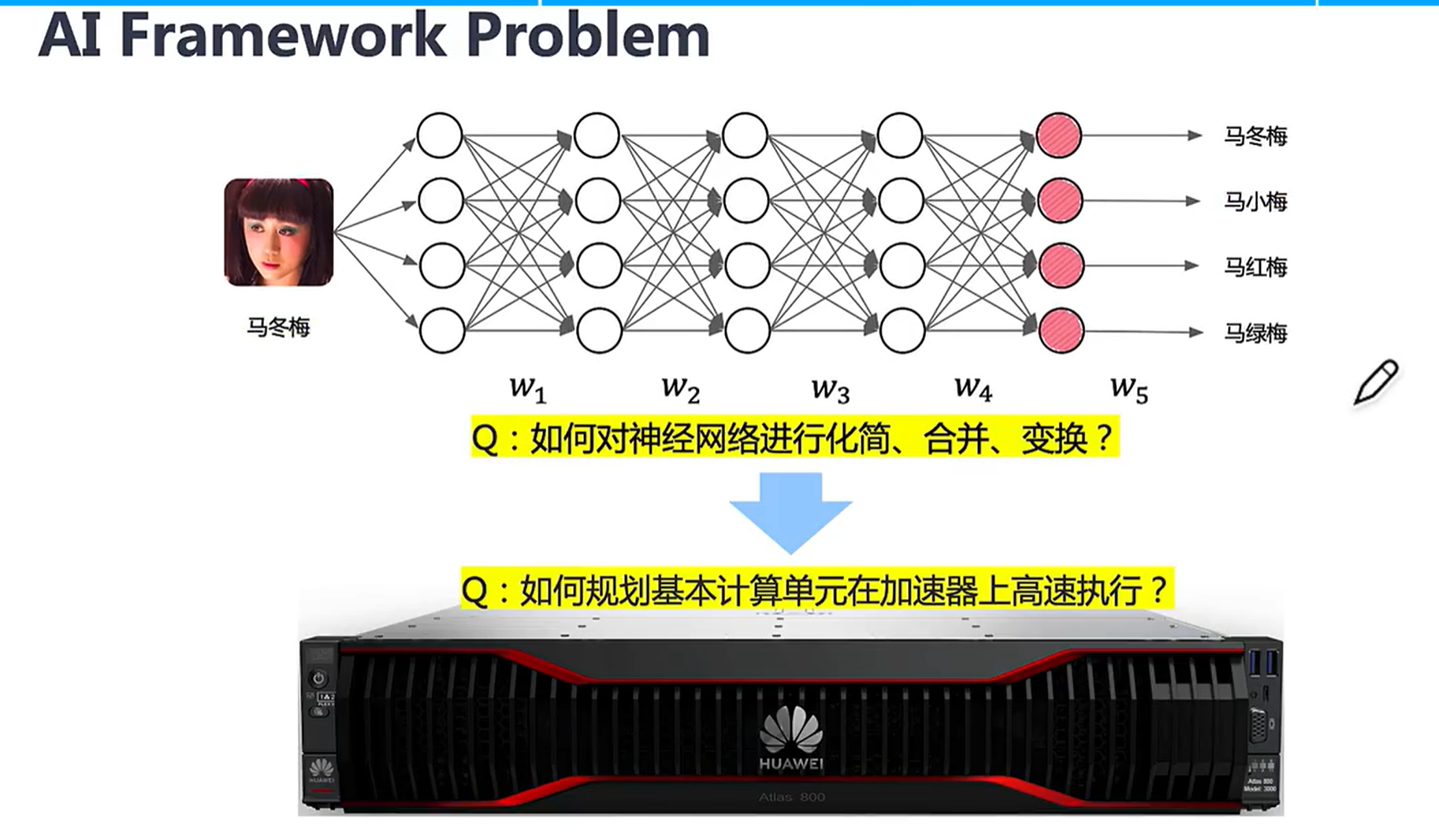
深度学习如何进行运行时管理?如何编译呢?如何适配不同后端?
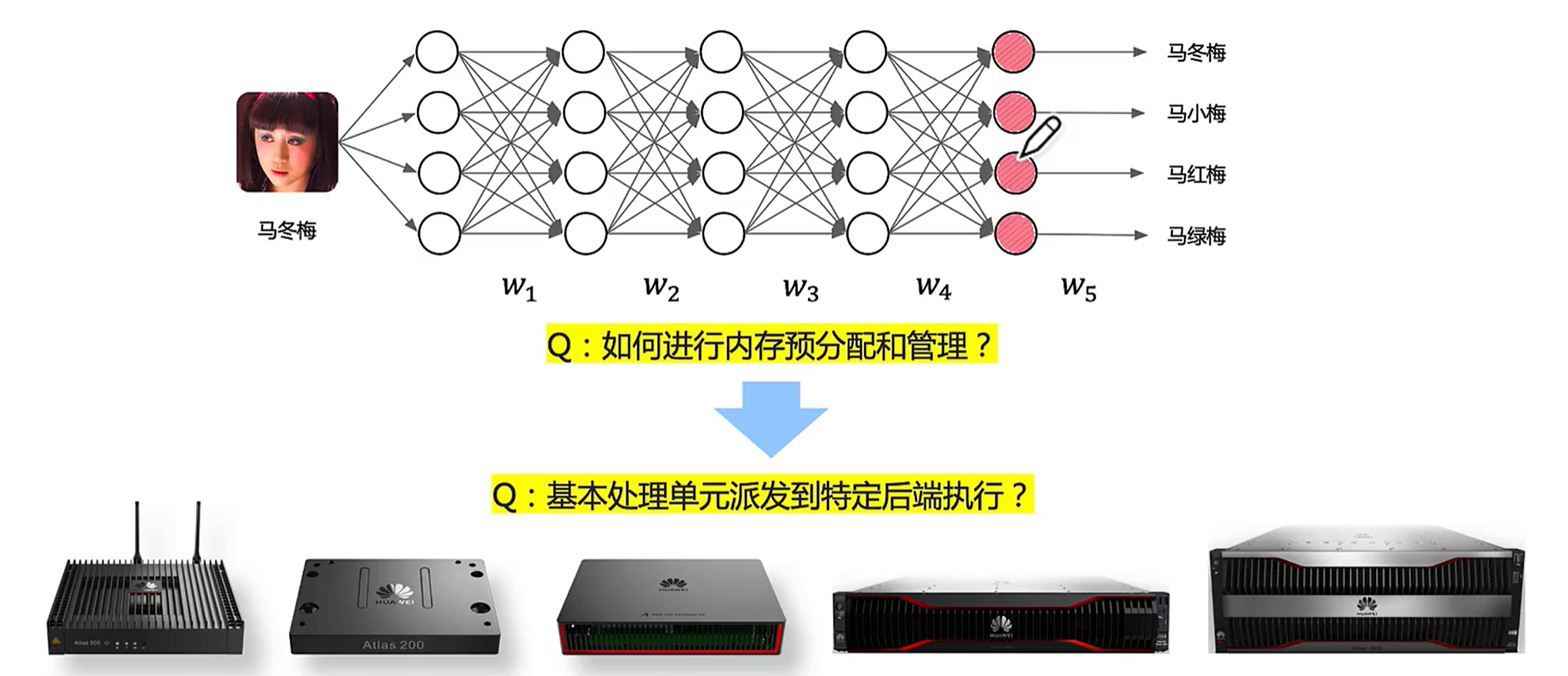
综上所述,我们先给出了统一表示——计算图
2.2基于计算图的基本框架组成

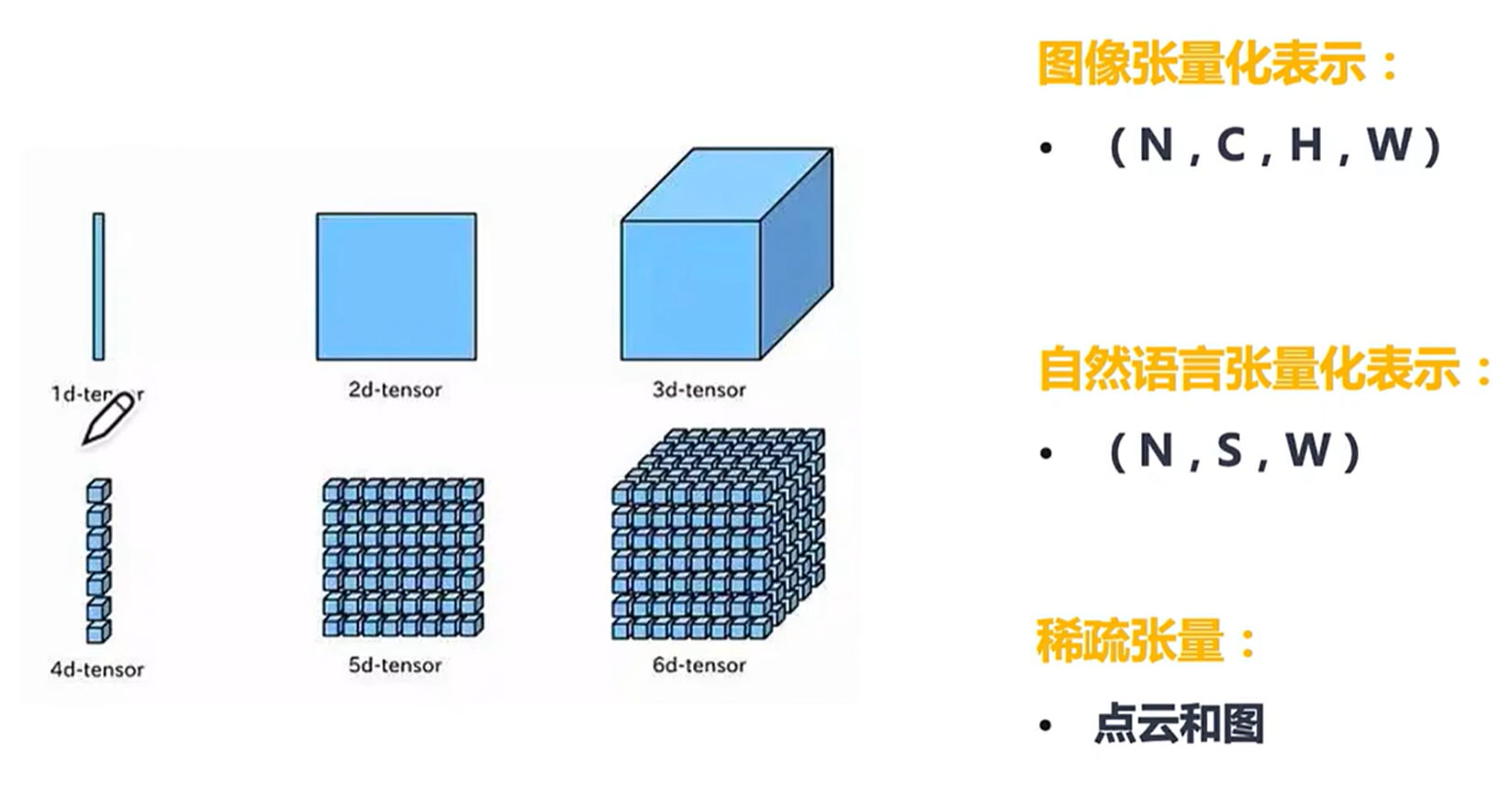
形状这么理解(从3,2,5反着理解):我们有个元素为5的数组,然后这样的数组有两排;这样两排的数组一共有三大块。
为什么使用张量而不用其他数据结构的优点如上所述。上层表示为张量数组,说明有了统一数据结构可以做一个统一的内存映射,方便做切片等操作。'
2.3不同数据的张量化表示
2.4基于计算图的计算框架
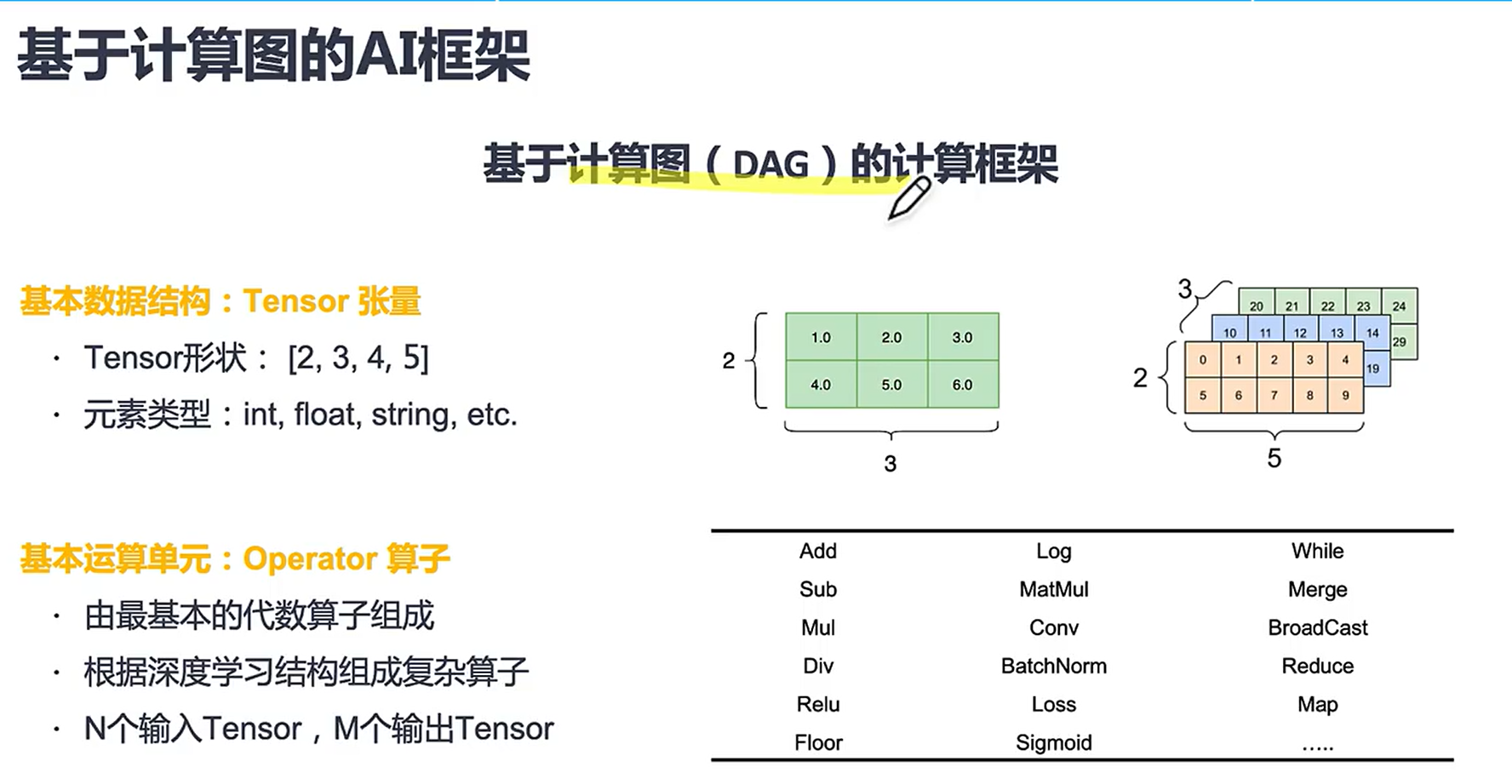
算子有大有小,小到加减乘除大到右边的那些一堆。
计算图(DAG)计算框架
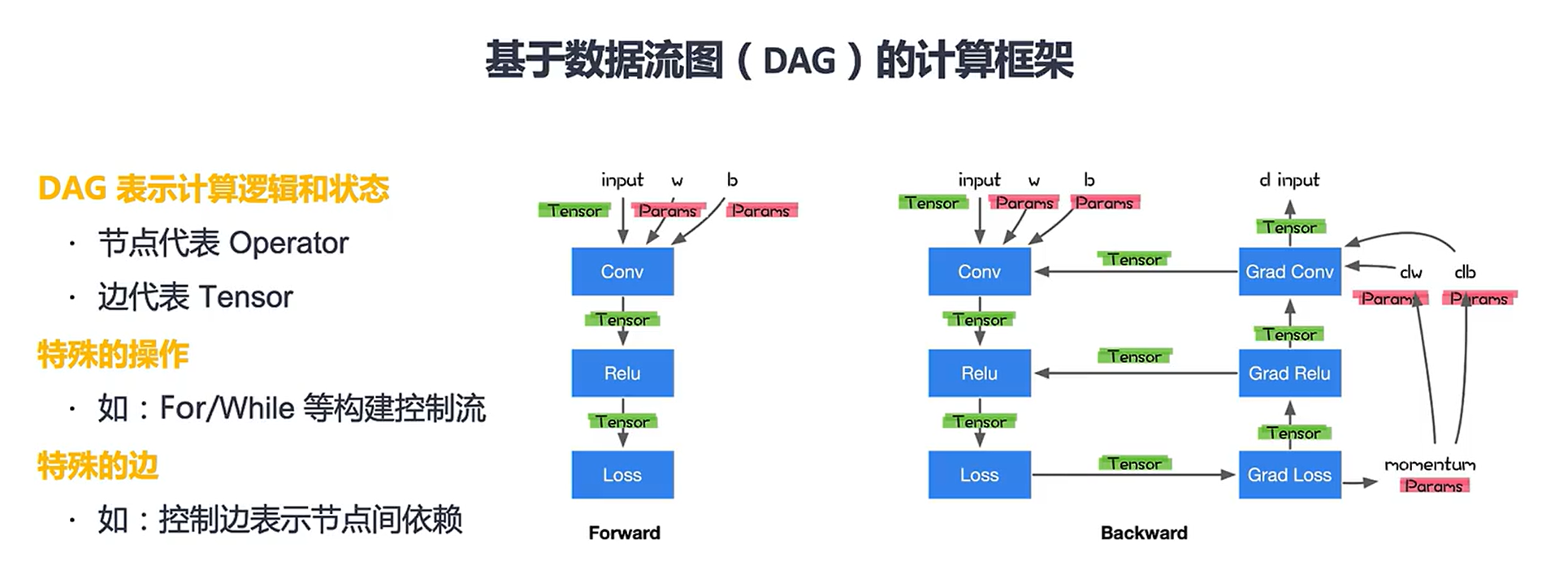
特殊的操作会复杂化计算图。(后续会说)
这里说的计算图比较简略,想看详细的版本可参考:
深度学习入门与Pytorch|2.1 计算图的概念与理解 - aHiiLn的文章 - 知乎 https://zhuanlan.zhihu.com/p/412542969
第三节-怎么用计算图表示自动微分
3.1复习训练过程
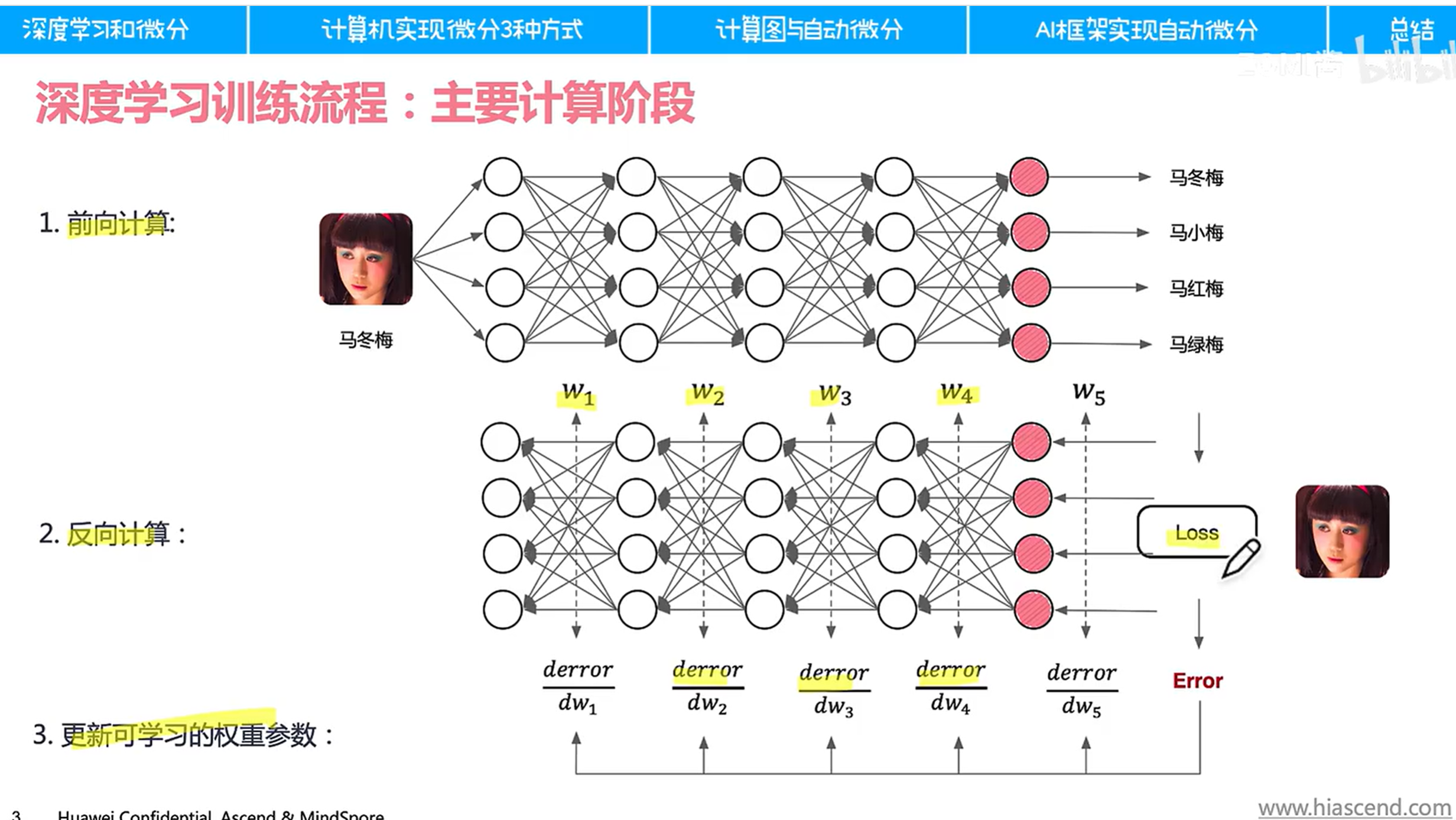
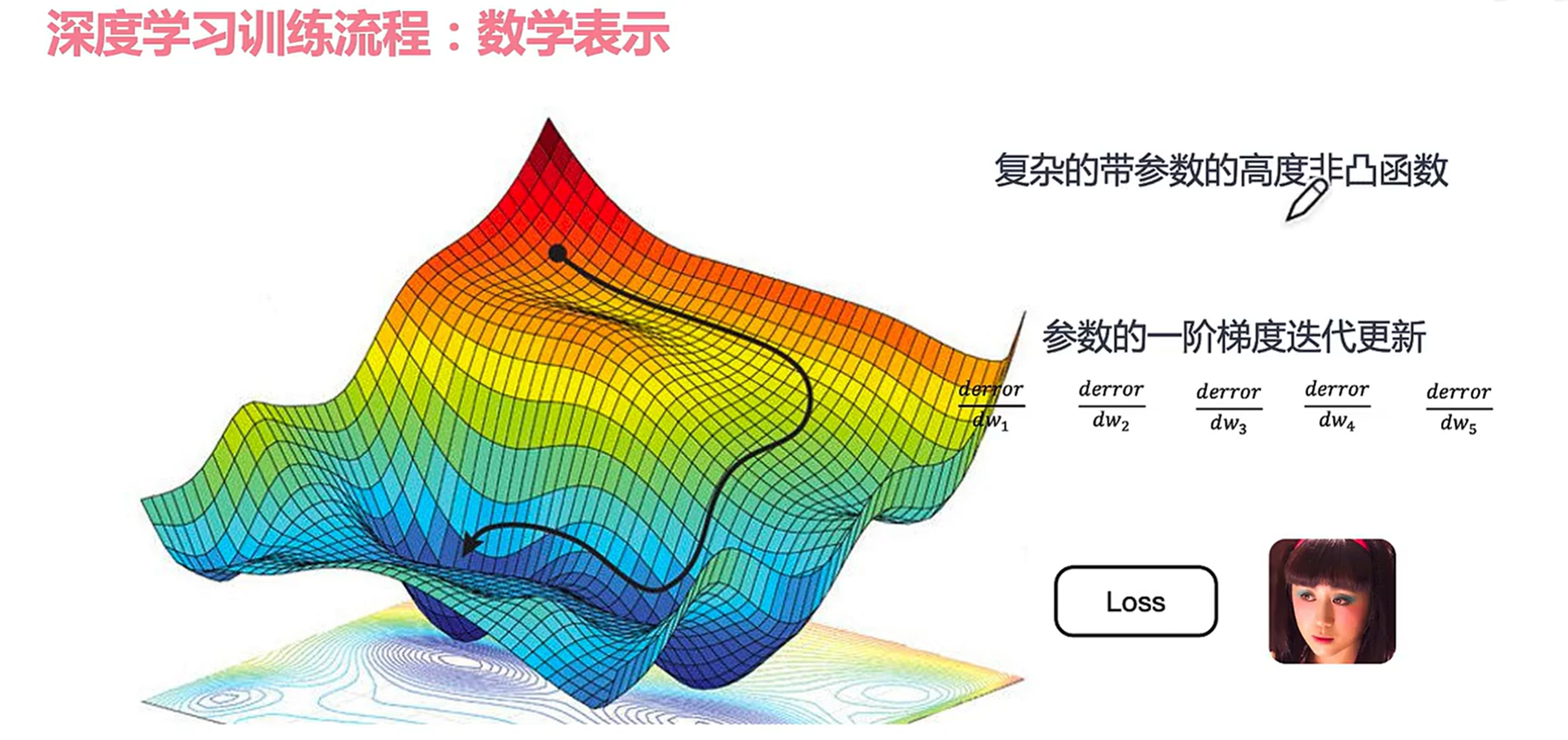
反向传播过程就是为了找到最小鞍点(高度非凸函数)

为什么说自动生成反向计算程序?是因为前向是人工构造的;反向很复杂,我们希望系统可以帮助我们构建。
3.2反向传播与微分
比如这样的一个网络模型(我们只写了正向传播)
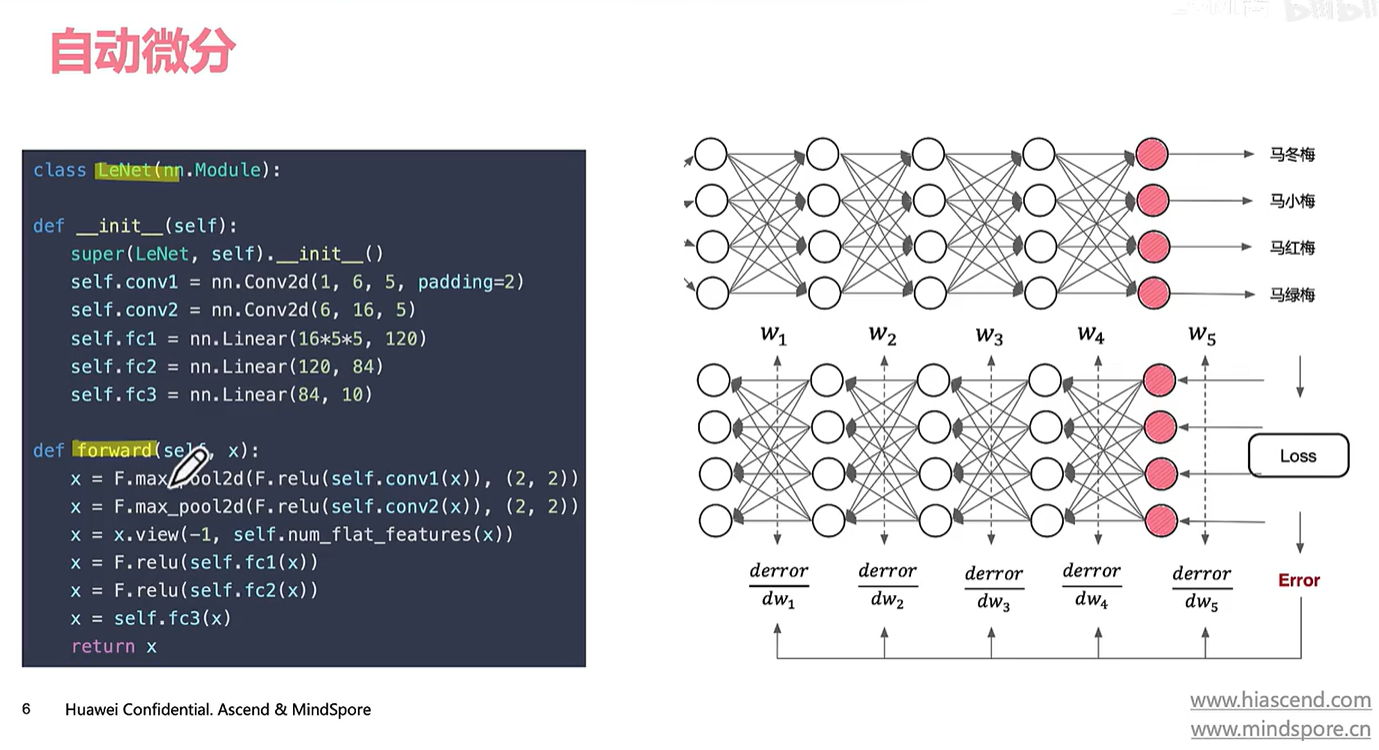
那右边的反向程序怎么办?不能手写,希望框架能够自动帮我们构建(构建DAG的有向无环图,即计算图表达我们的正向和反向)
我们回顾一下自动微分里面涉及到的简单微分方式:
首先是符号微分:

(注意到表达式膨胀以及无法求导的算子)
第二种方法——数值微分

3.3自动微分
第三种方式——自动微分!
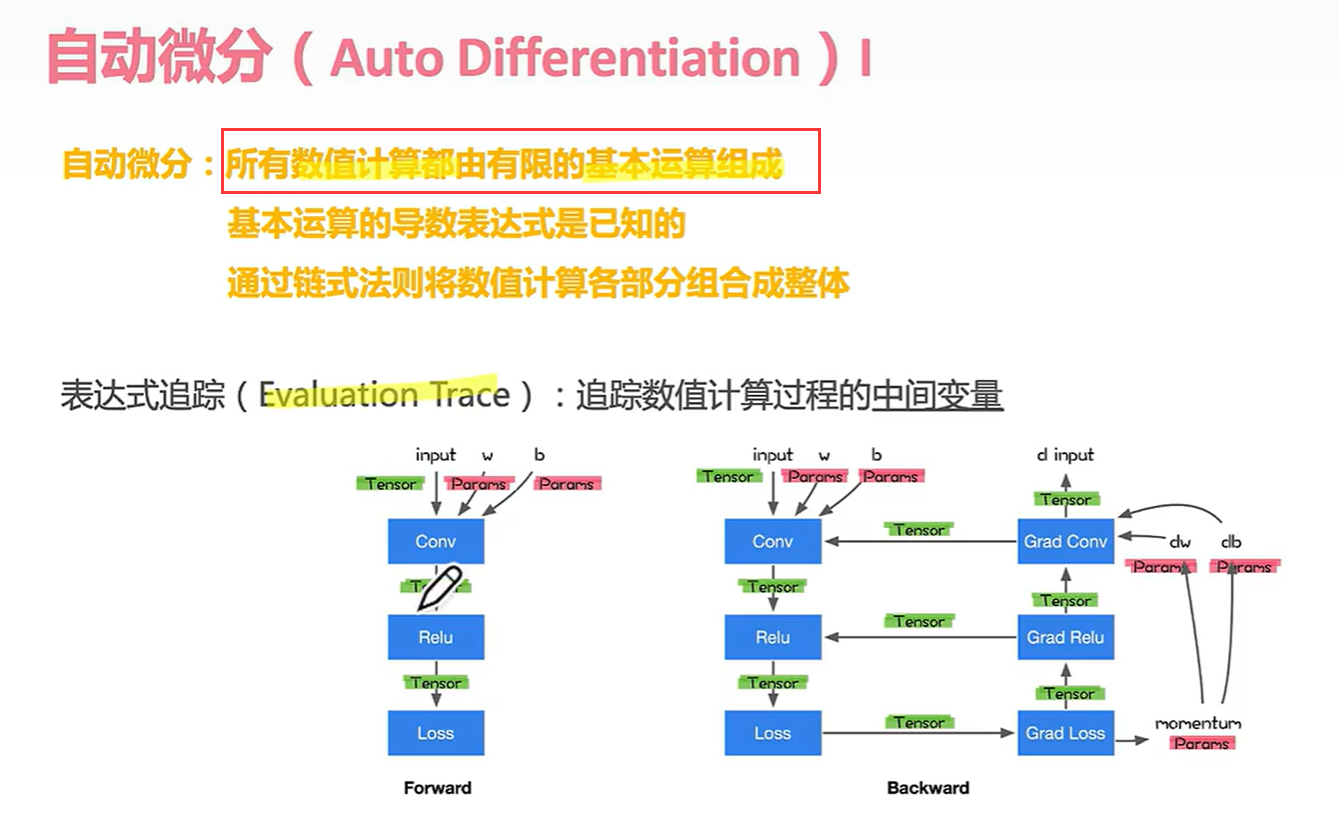
那么什么是中间变量呢??
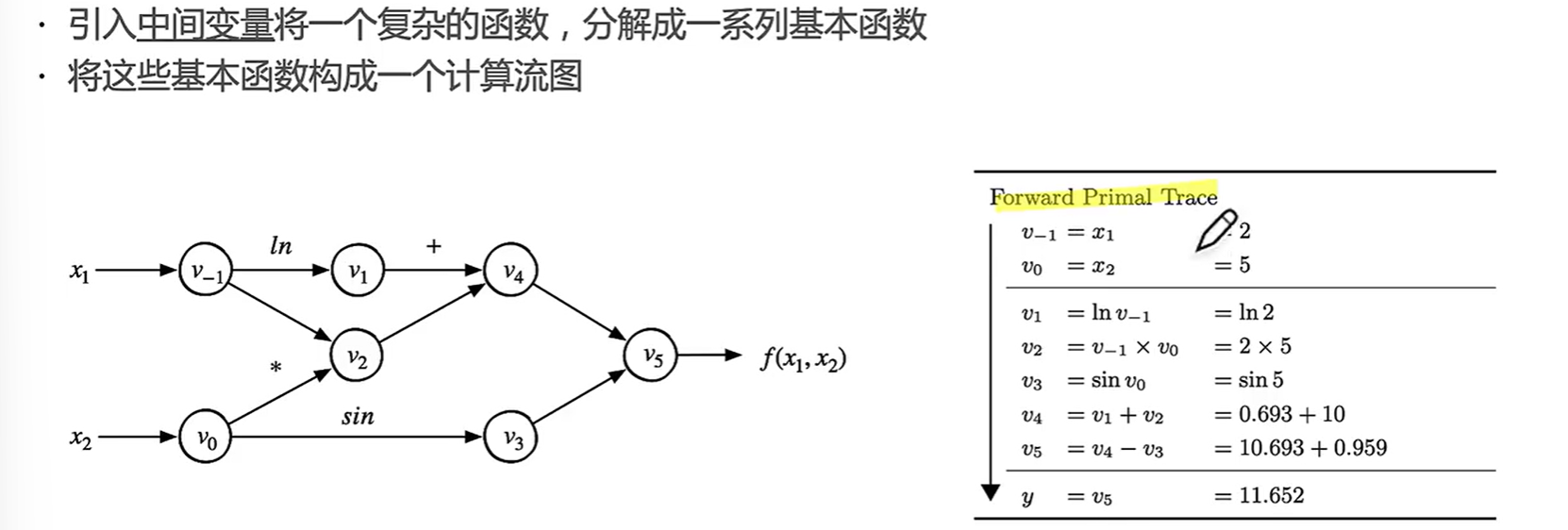
比如v-1到v5都是中间变量。每经过一个边运算产生一个中间变量。(分治法)
前面看的是正向的,我们再看看反向。
在反向传播中,偏导数也算中间变量。
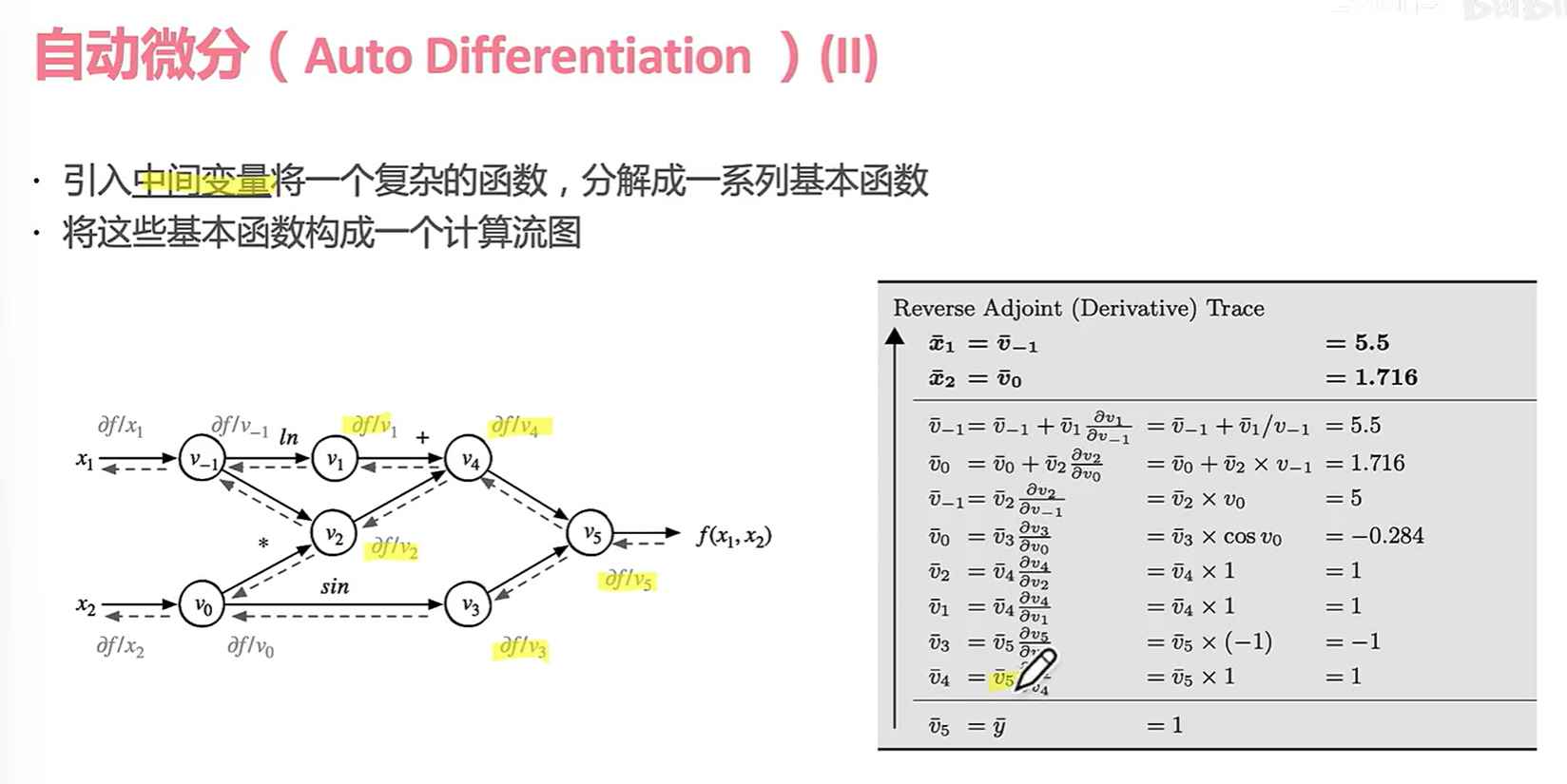
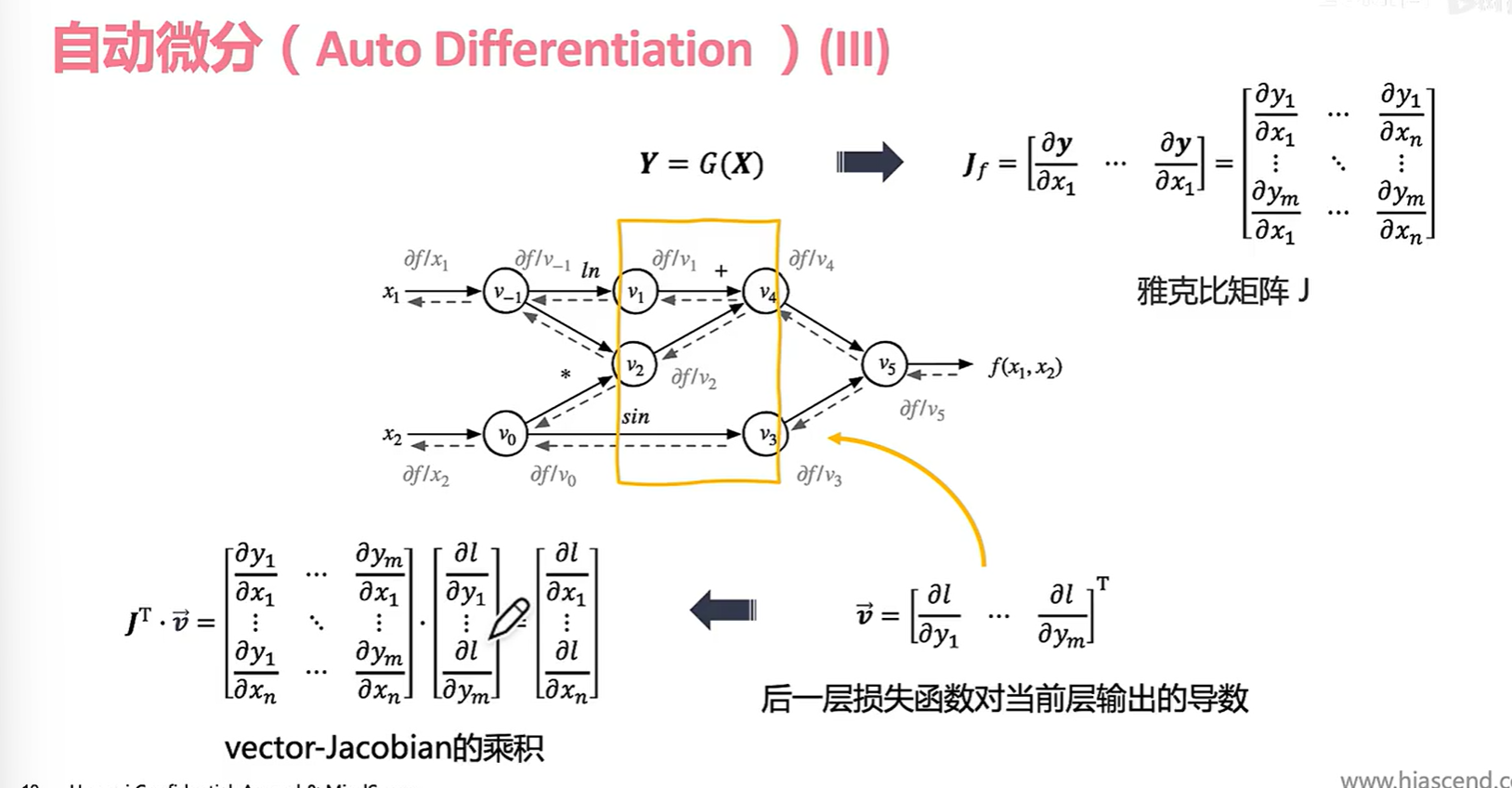
黄色部分是神经网络的“一层”,把他当成一个抽象函数 Y = G(X) ,其中X是v1,v2组成的一个抽象张量;输出Y就是v3,v4。
为了更好的在数学上表示Y对X的导数我们引入了雅可比矩阵。 我们计算完最终的导数f(x1,x2)后就要开始反向传播的过程。 我们在v4,v3反向传播的时候先暂时把它当作:

(实际上这个玩意儿是为了求反向输出:)

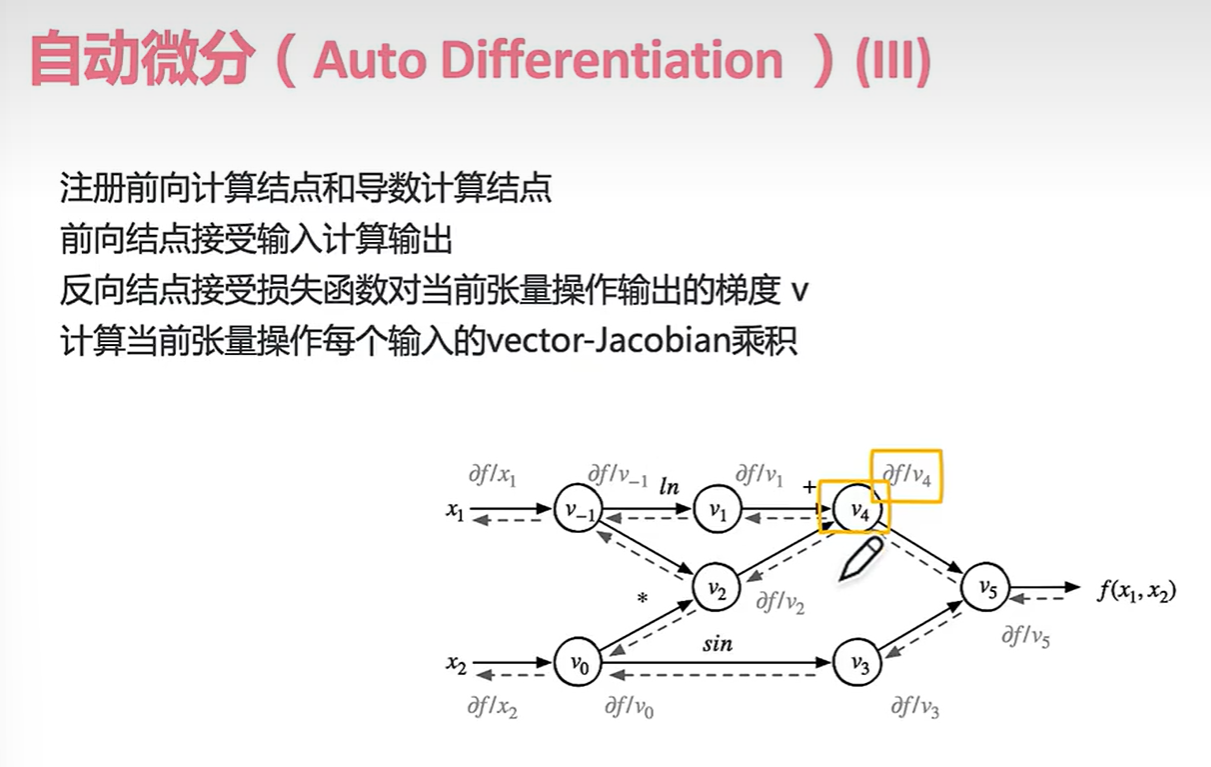
可以看出每个结点无论前后都是接受输入给出输出。
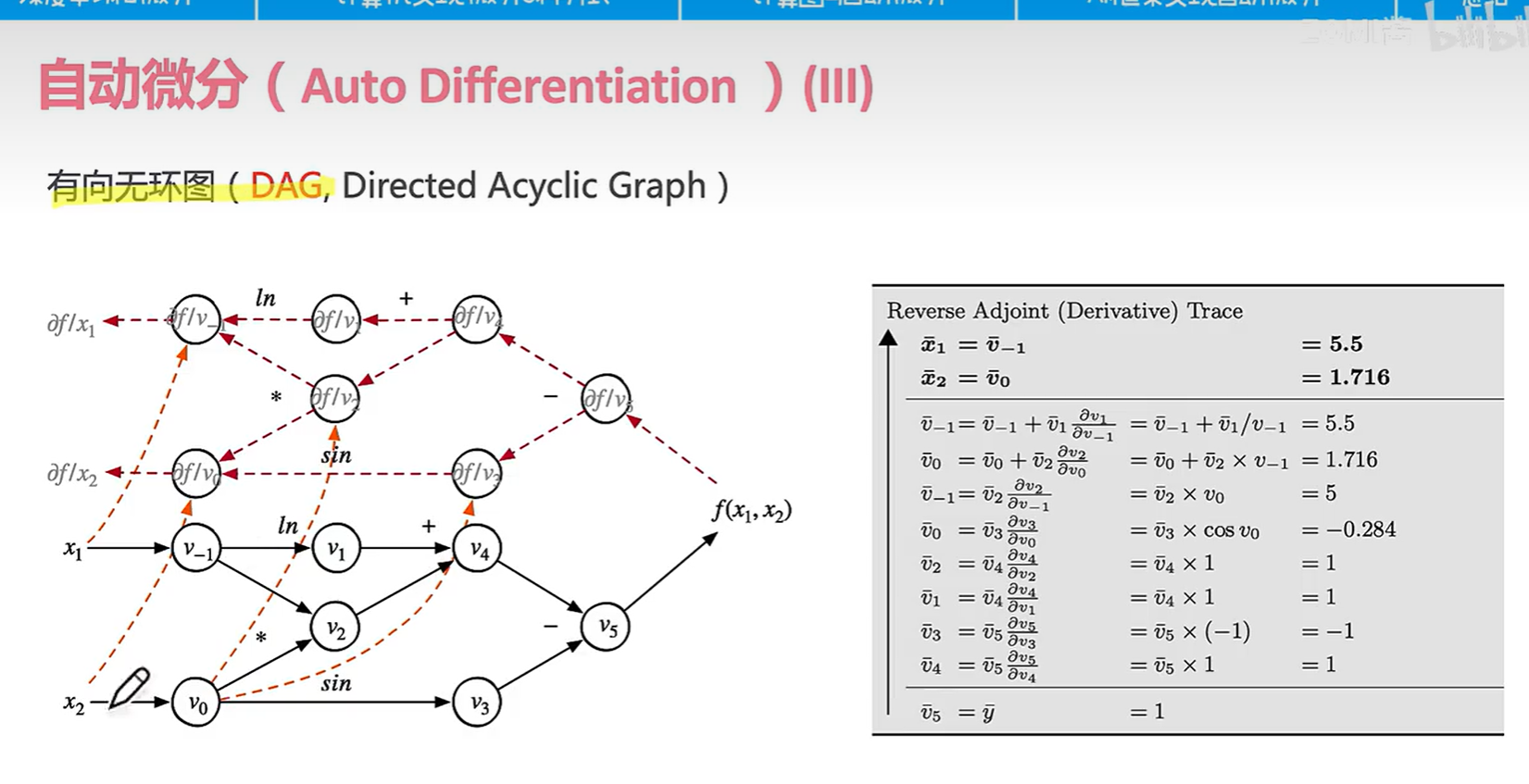
我们把计算图分离出来看是这样的,注意到有时候我们还是会用到正向的变量,所以我们要吧中间变量存下来。所以说占据显存。。。因为神经网络会存大量的中间变量数据。
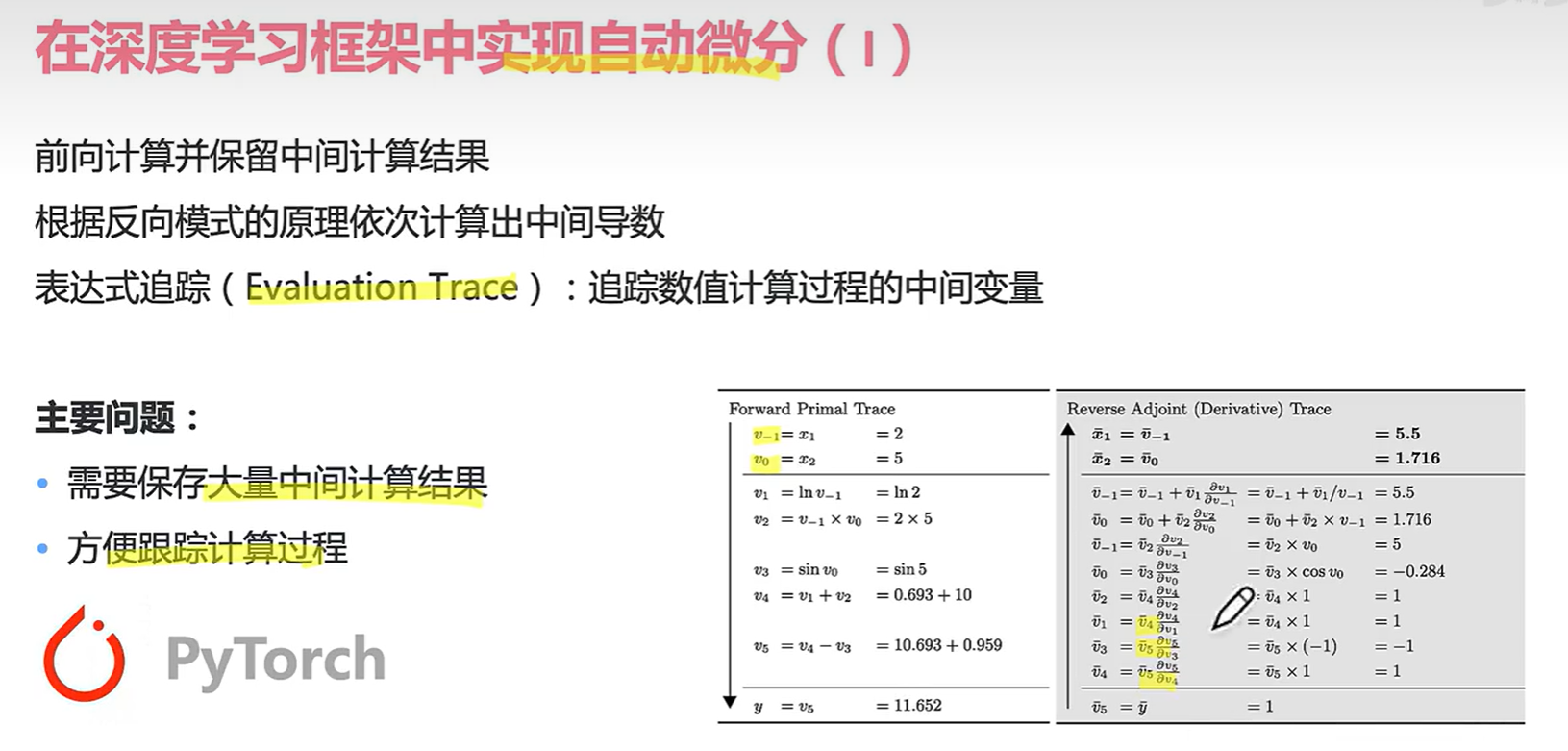
两个小问题:

接下来看几种自动微分的形式:
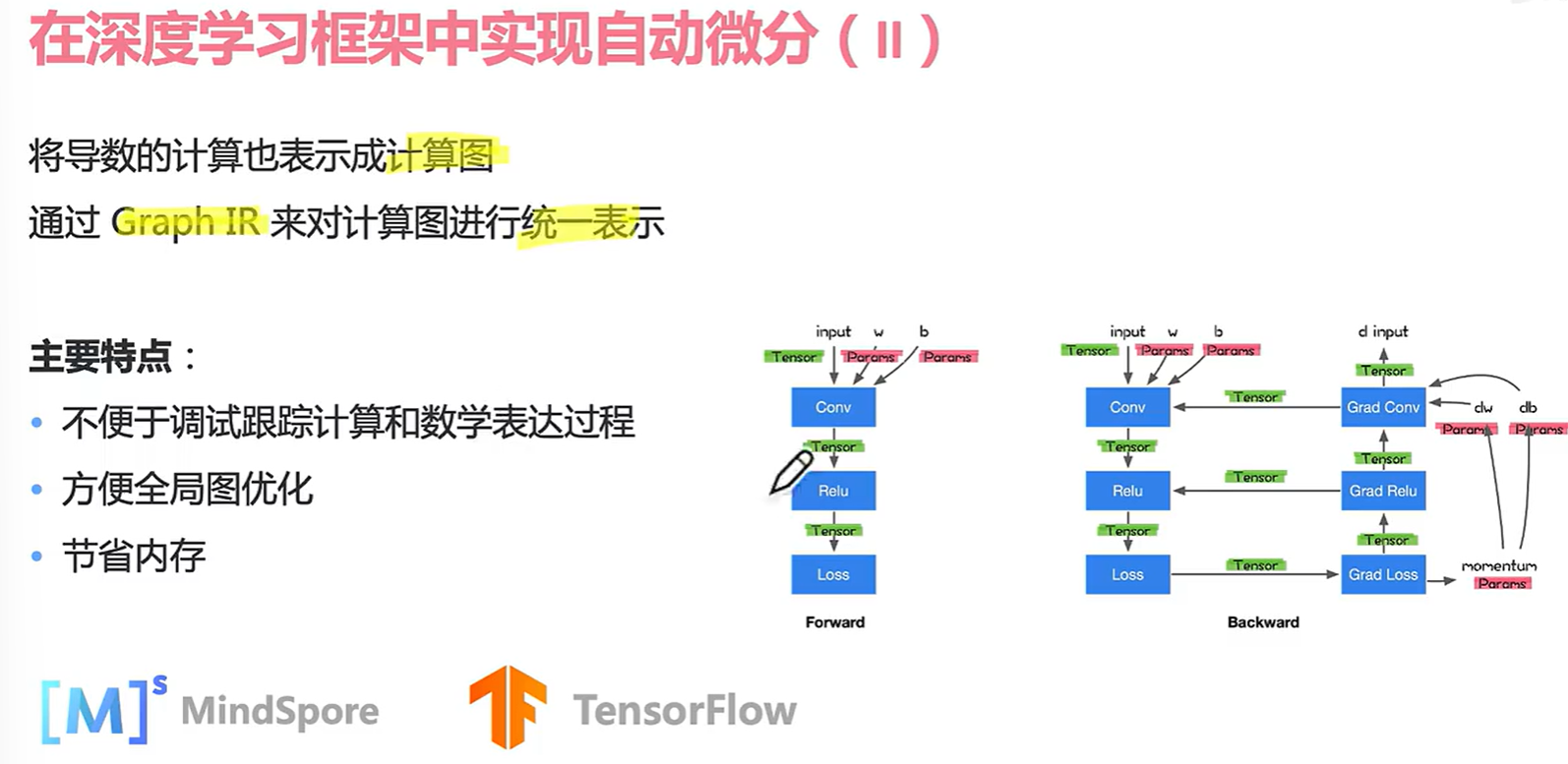
看一下mindspore的优化实现
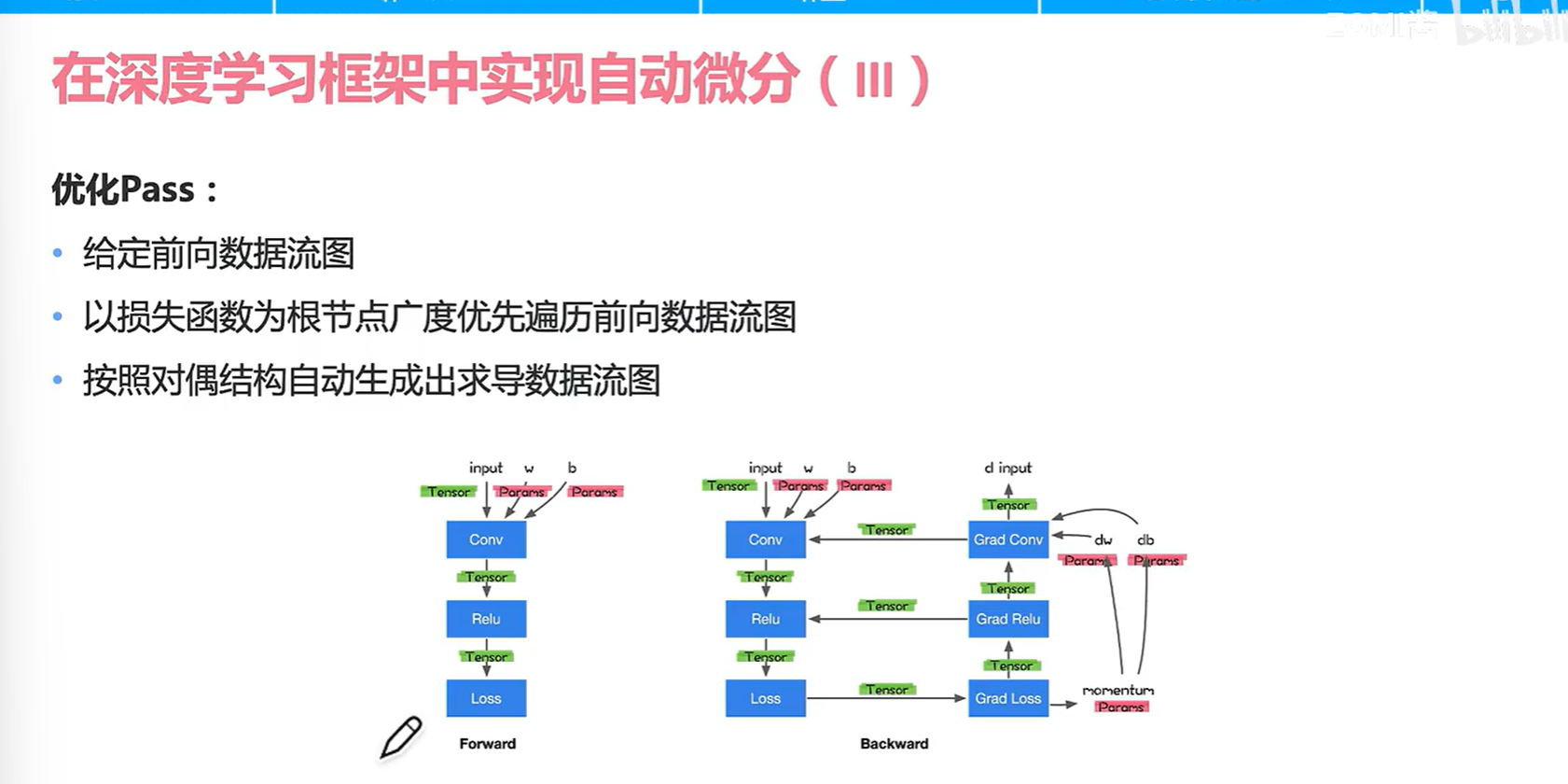
最后复习一下,有了某个语言表示的计算图(正向)然后有了自动微分,有了正反向的计算图,然后就可以成为深度学习训练之前的完整的计算图。
3.4 pytorch和tensorflow的区别
这个是自己的额外整理部分。以这样一个计算图为例:
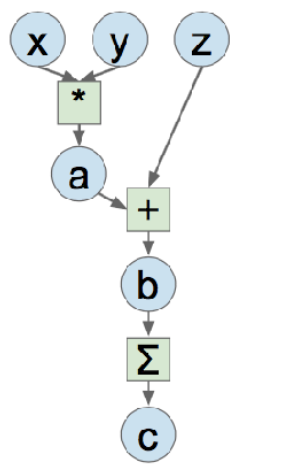
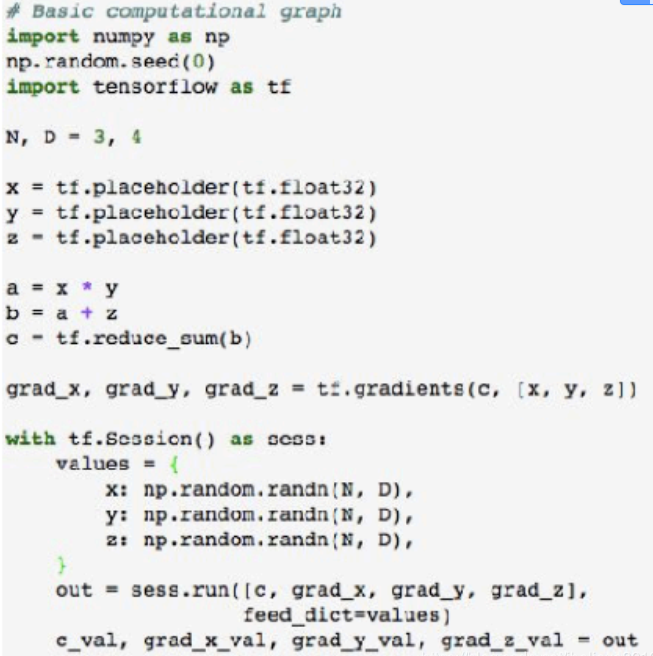

左边是tensorflow的静态图,先构建然后进入运行时;右边是torch动态图,相当于每一个输出都可以在不同环节得到。类似静态编译和动态编译。
左图从代码中可以看出静态结构,因为我们可以看到,一旦在一个会话中,我们不能定义新的操作(或节点),可使用sess.run()方法中的feed_dict属性来改变输入变量。他的缺点是:
- 对可变维度输入的扩展性很差。例如,一个CNN(卷积神经网络)架构有一个静态的计算图,在28×28的图像上训练,如果没有大量的预处理模板代码,在不同尺寸的图像(如100×100)上就不会有好的表现。
- 调试性差。这些都是很难调试的,主要是因为用户无法接触到信息流是如何发生的。 erg:假设用户创建了一个畸形的静态图,用户无法直接跟踪这个错误,直到TensorFlow会话在计算反向传播和前向传播时发现一个错误。当模型巨大时,这就成为一个主要问题,因为它既浪费了用户的时间又浪费了计算资源。
pytorch动态图相关的优点为:
- 对不同维度输入的可扩展性。对不同维度的输入有很好的扩展性,因为新的预处理层可以动态地加入到网络本身。
- 调试容易。这些都是非常容易调试的,也是很多人从Tensorflow转向Pytorch的原因之一。由于节点是在任何信息流经它们之前动态创建的,因此错误变得非常容易发现,因为用户完全控制了训练过程中使用的变量。
第四节 计算图优化和执行
4.1 图优化
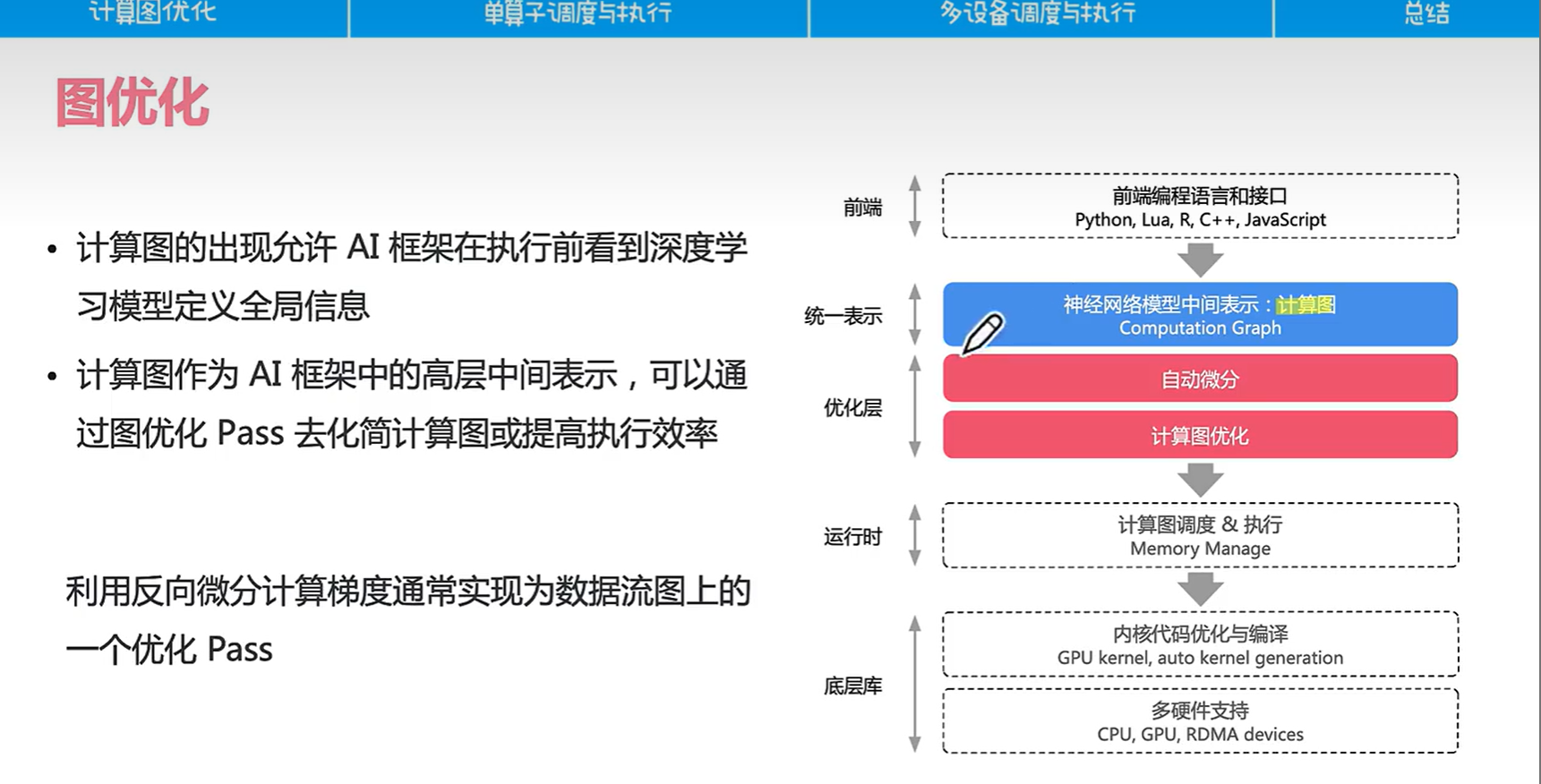
计算图的好处是作为高层IR表现,把前端具体实现和后者优化隔离。
计算图的优化是编译器做的:
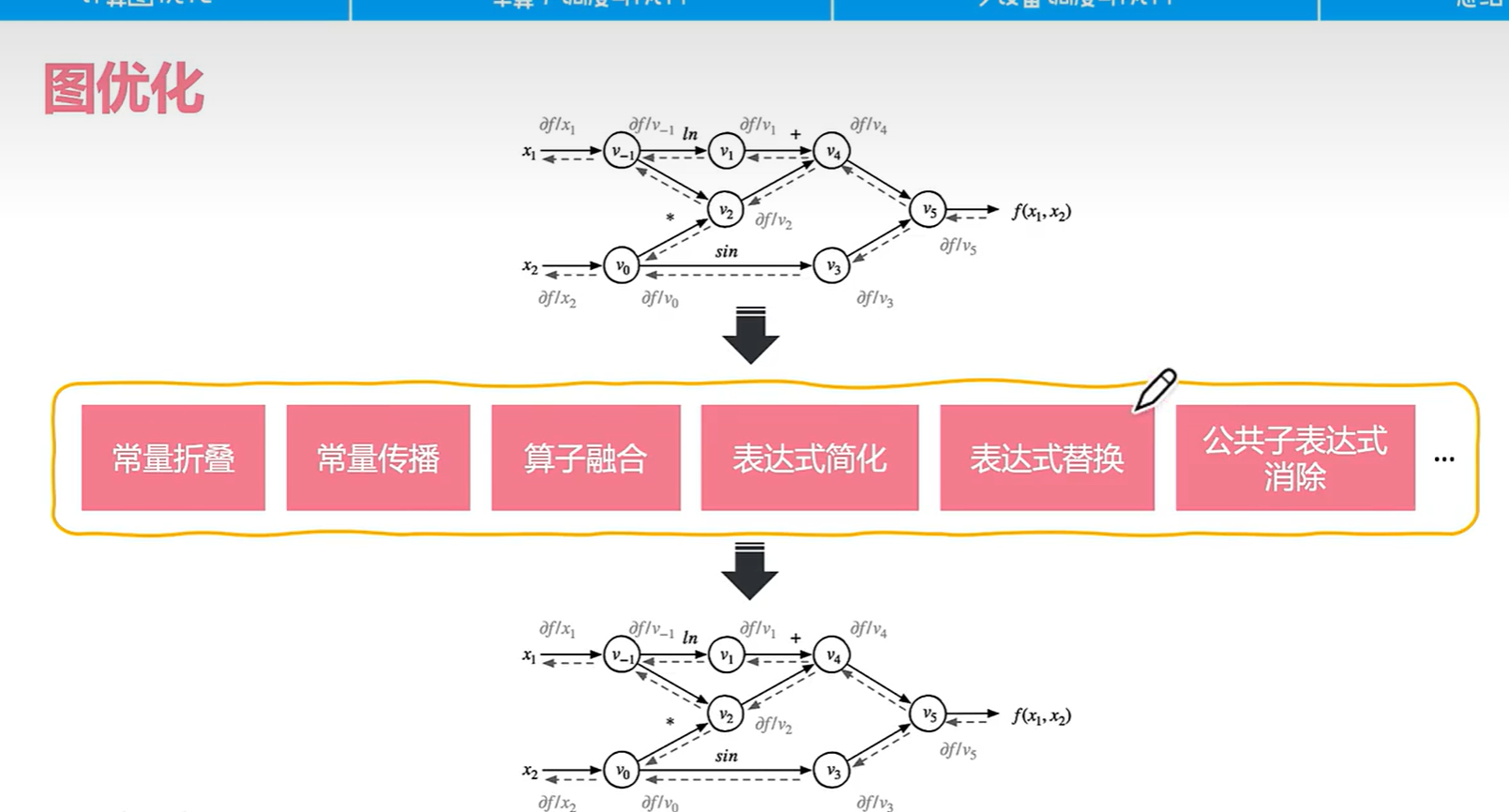
- 常量折叠:有些常量计算比如1+1可以在编译期就算出来,没必要在运行时计算
- 常量传播:常量传播,顾名思义,就是把常量传播到使用了这个常量的地方去,用常量替换原来的变量。https://www.modb.pro/db/524829
- https://blog.csdn.net/qq_36287943/article/details/104974597
- 算子融合:小算子变成大算子
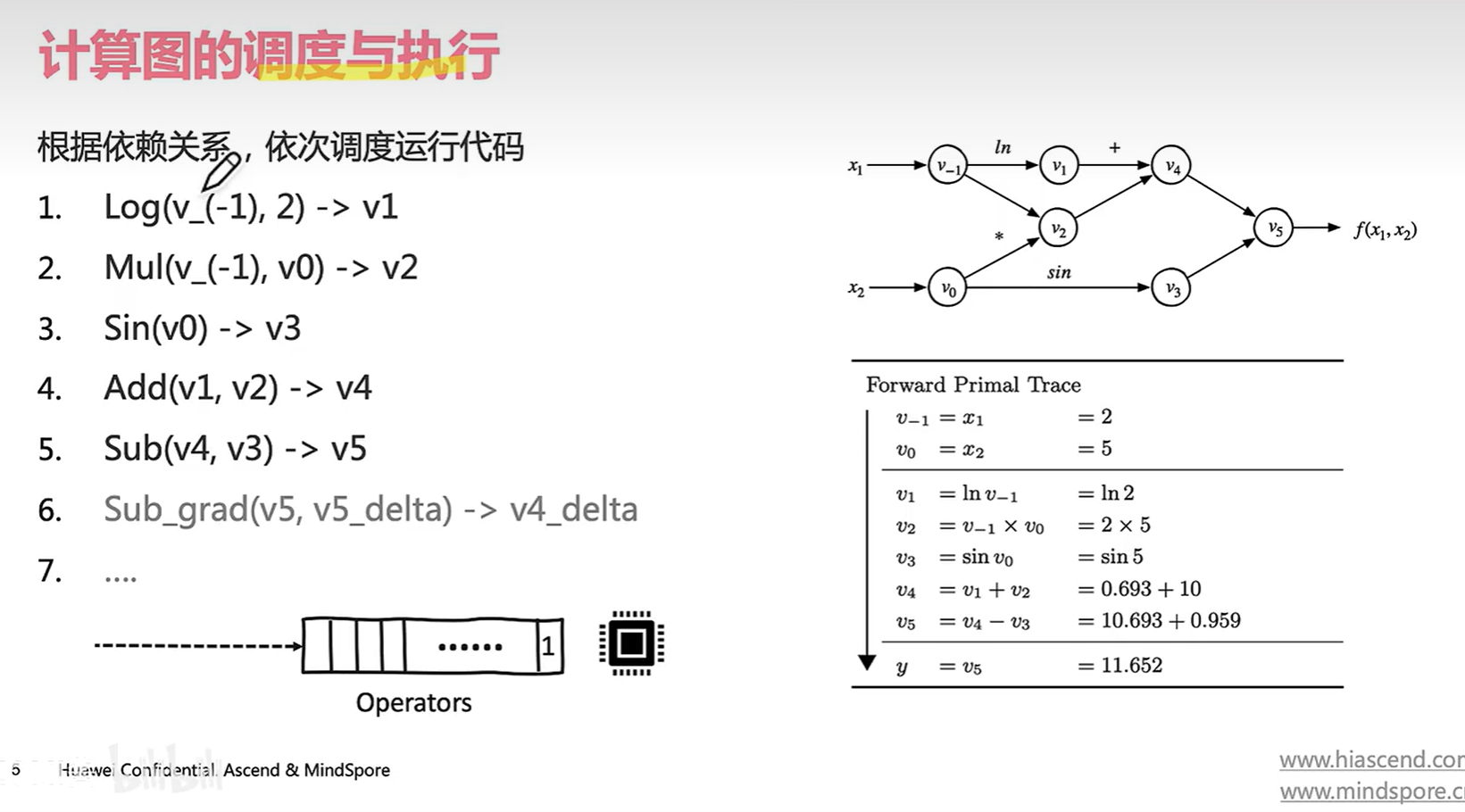
7 是一些反向的操作。。。(如下图显示)
他的计算时根据依赖关系丢到一个算子列表,然后计算单元根据我们的算子列表计算出结果。
4.2 算子调度
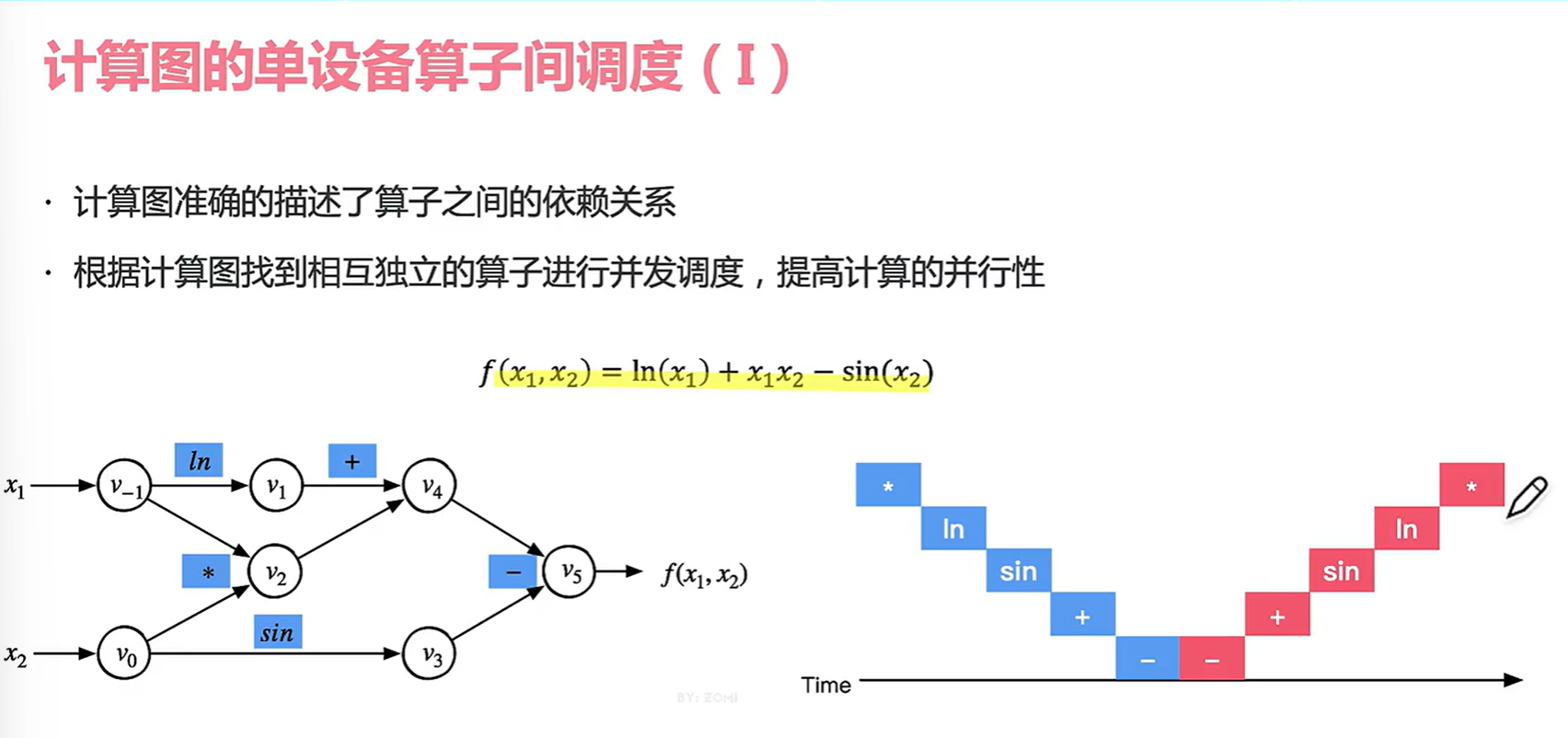
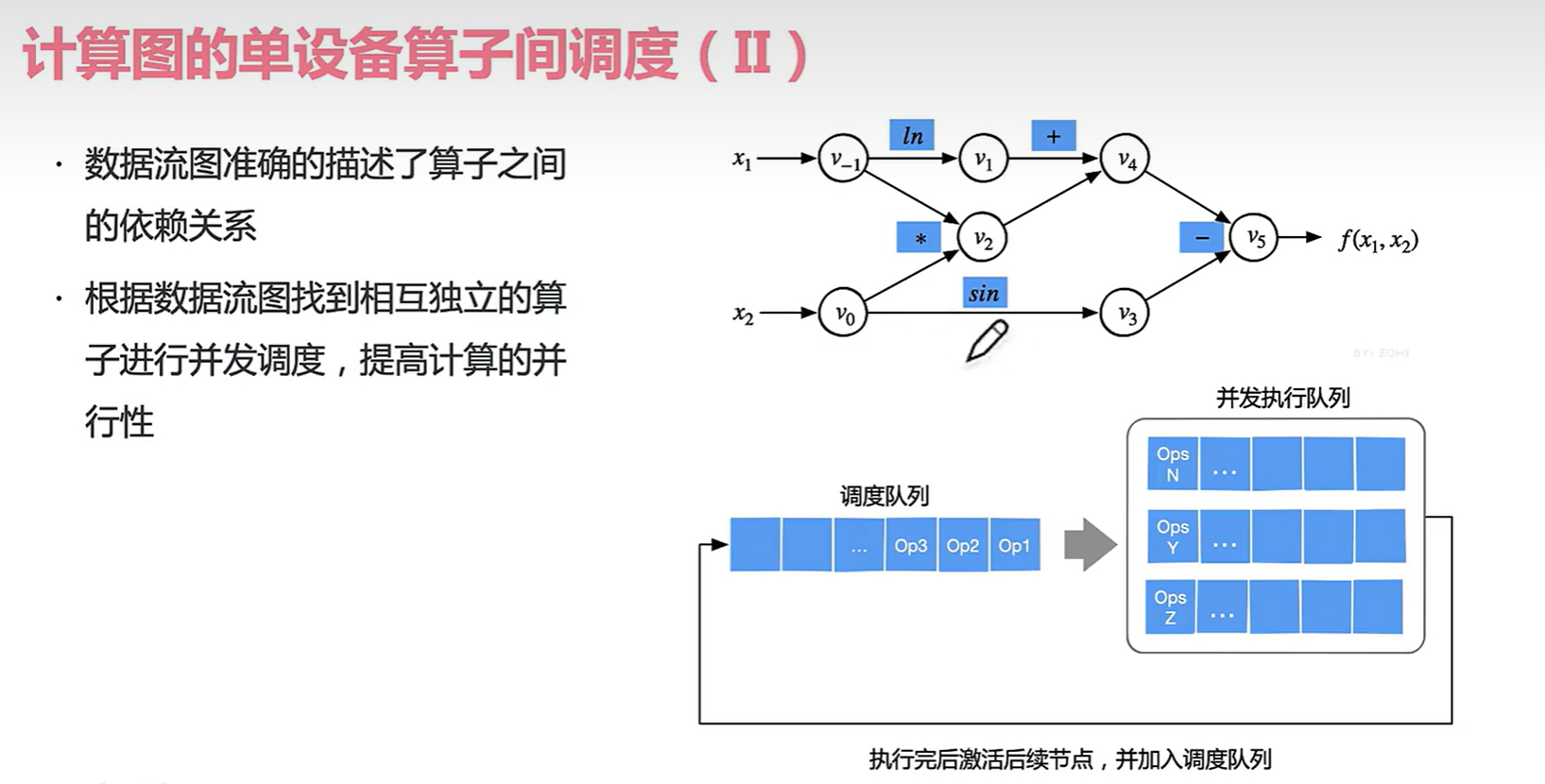
在不同的线程池并行(多计算核)可以提高我们的算子计算速度。

假设我们有四台计算设备,对于Inception模块,我们可能不同的算子模块会放到不同的计算设备中运行(下图左侧)
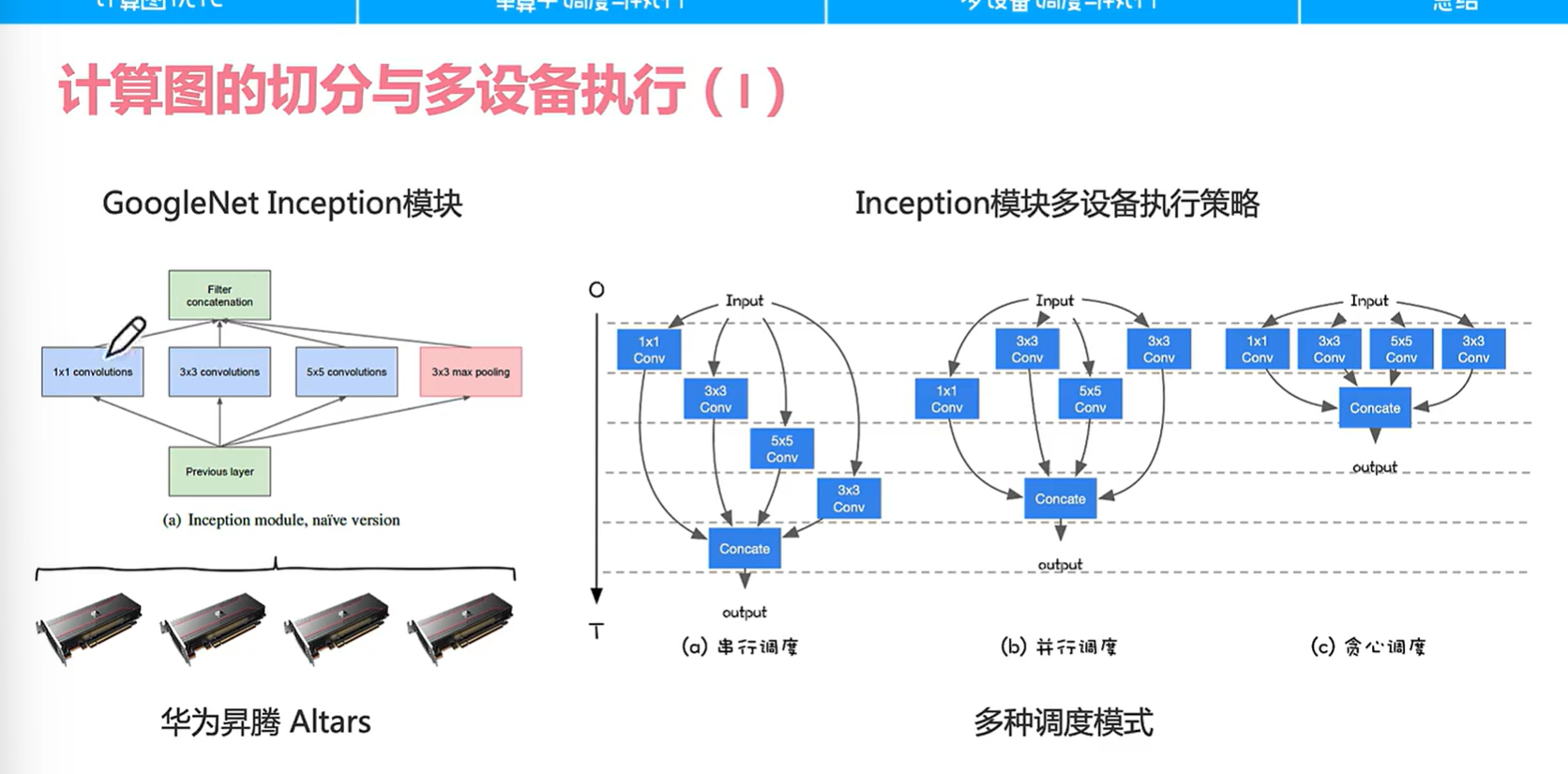
一旦放在不同设备就有多种调度模式,这里没那么简单,我们还要看看如何处理信息的切分(数据是怎么切分的?怎么分到不同的设备的?)
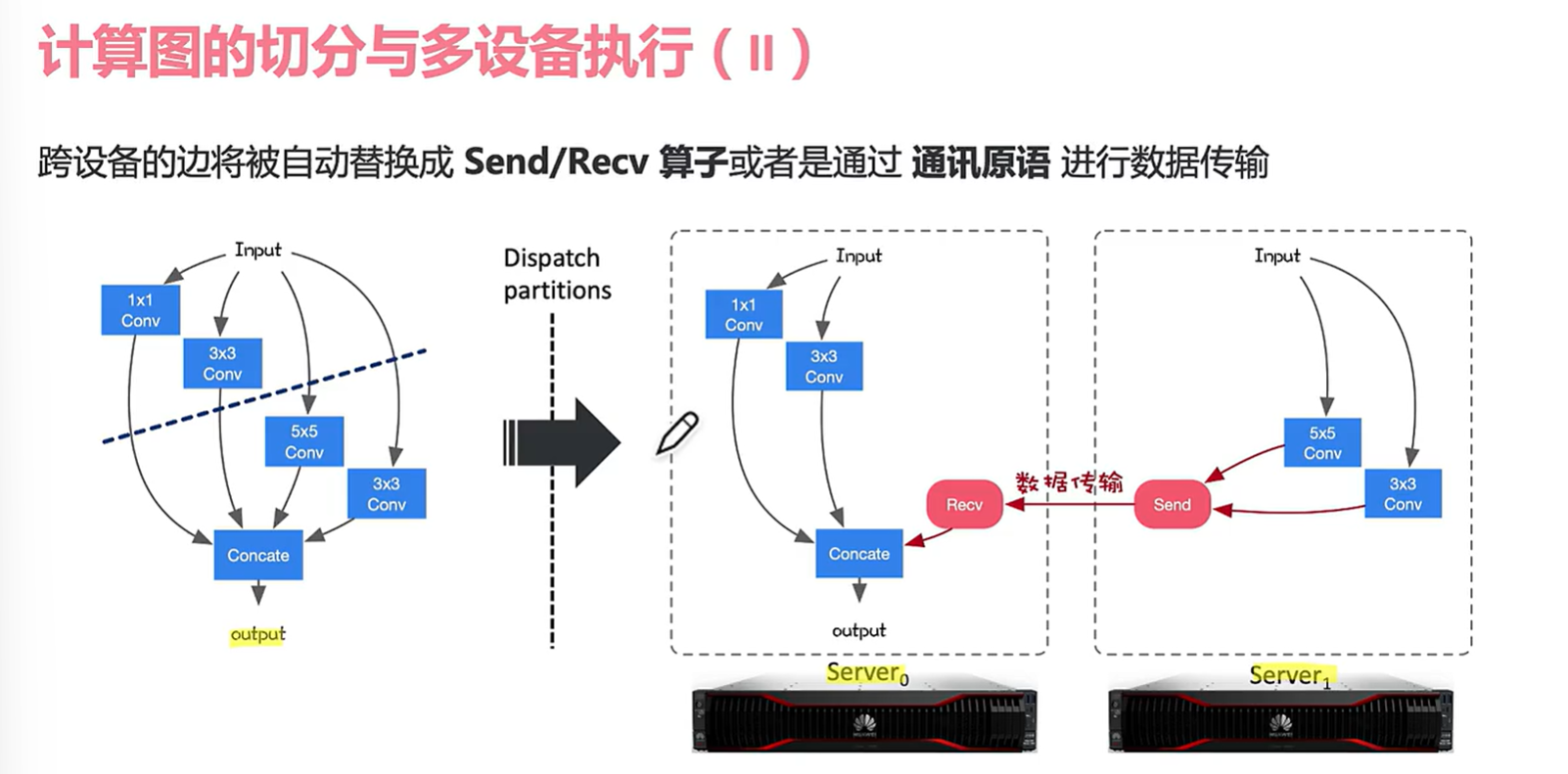
切分后可能通过send算子也可能是通讯原语进行传输。
有关通讯原语可参考openmmlab 的相关推文:
AI框架基础技术之深度学习中的通信优化
https://zhuanlan.zhihu.com/p/348982652
或本视频作者的文章:分布式训练硬核技术——通信原语https://zhuanlan.zhihu.com/p/465967735
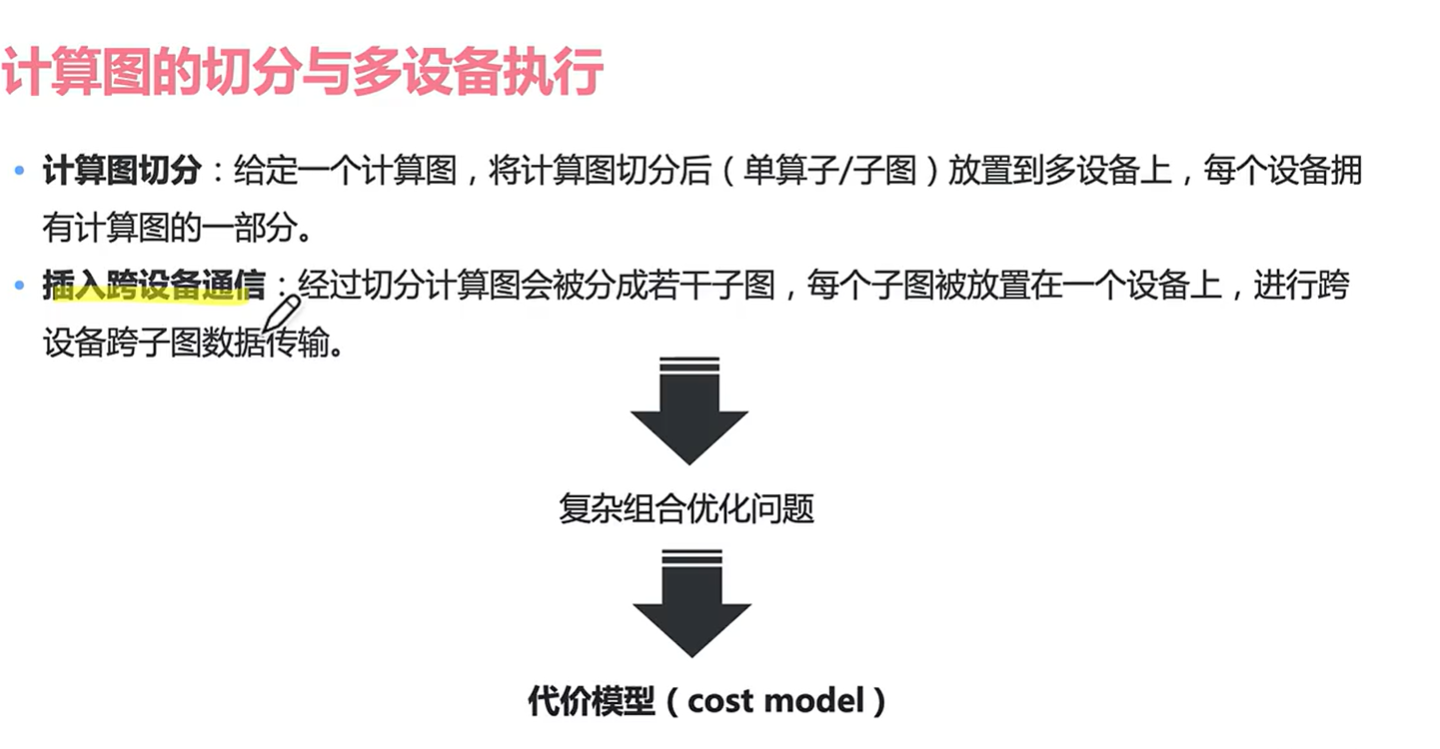
实际上这个是非常困难的问题,因为我要考虑计算图怎么切分,怎么切分可以让我的组合优化问题效率更高(对算子进行分发和通讯的手段)
第五节 AI框架如何表示控制流

AI框架在设计的时候就像做到前后端分离,为了解决这个问题提出了统一标识计算图,通过统一描述可以帮助前端用户更灵活编写算法;计算图也影响了后续优化方式和系统拓展;
5.1 控制流
以transformer为例:除了if还有很多for循环。
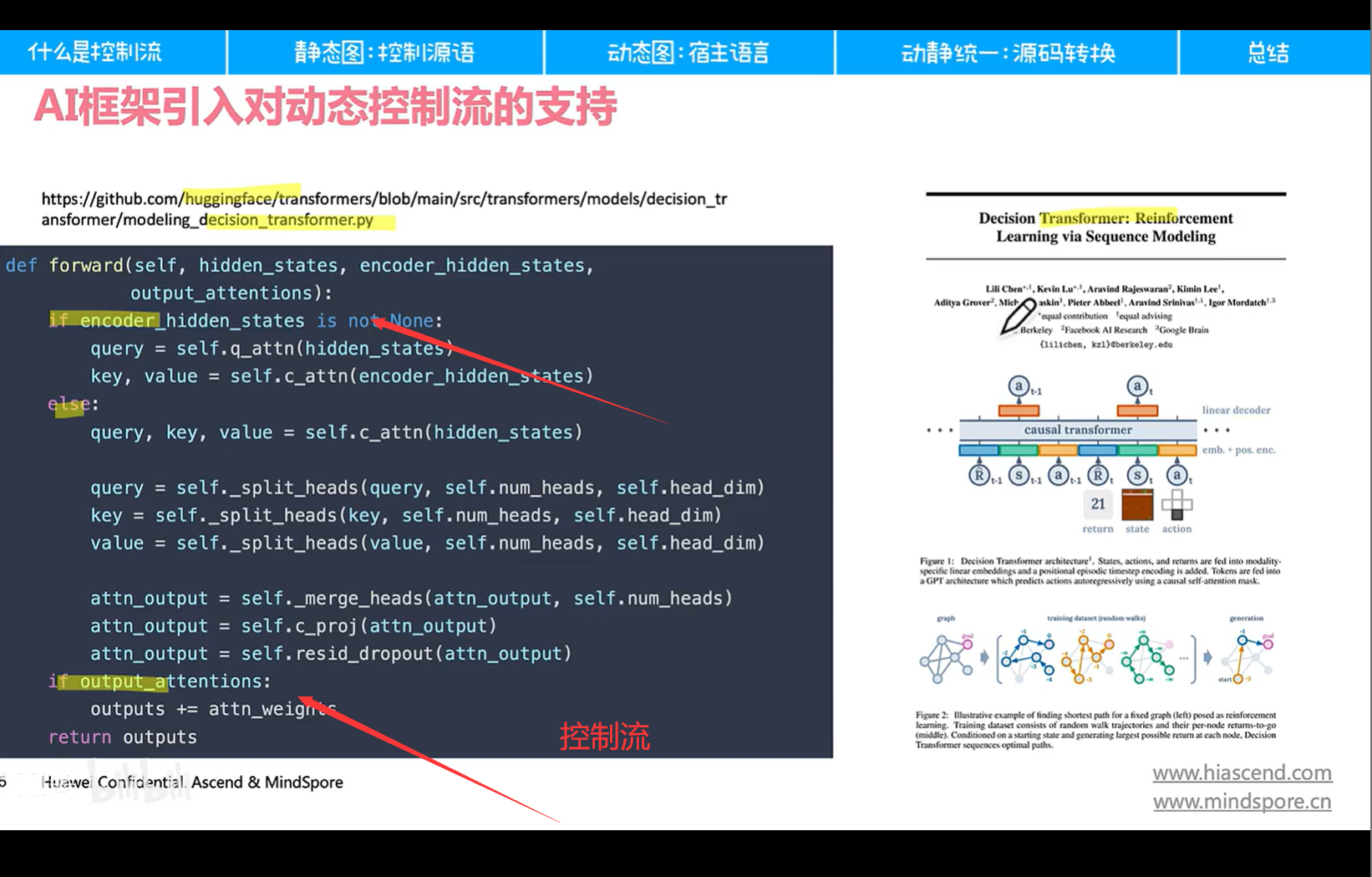
现在主流有了三种解决方案:(分别是ten py mindspore)

ten和torch最新版本也开始引入第三种方案。
5.2 tensorflow静态图控制流实现
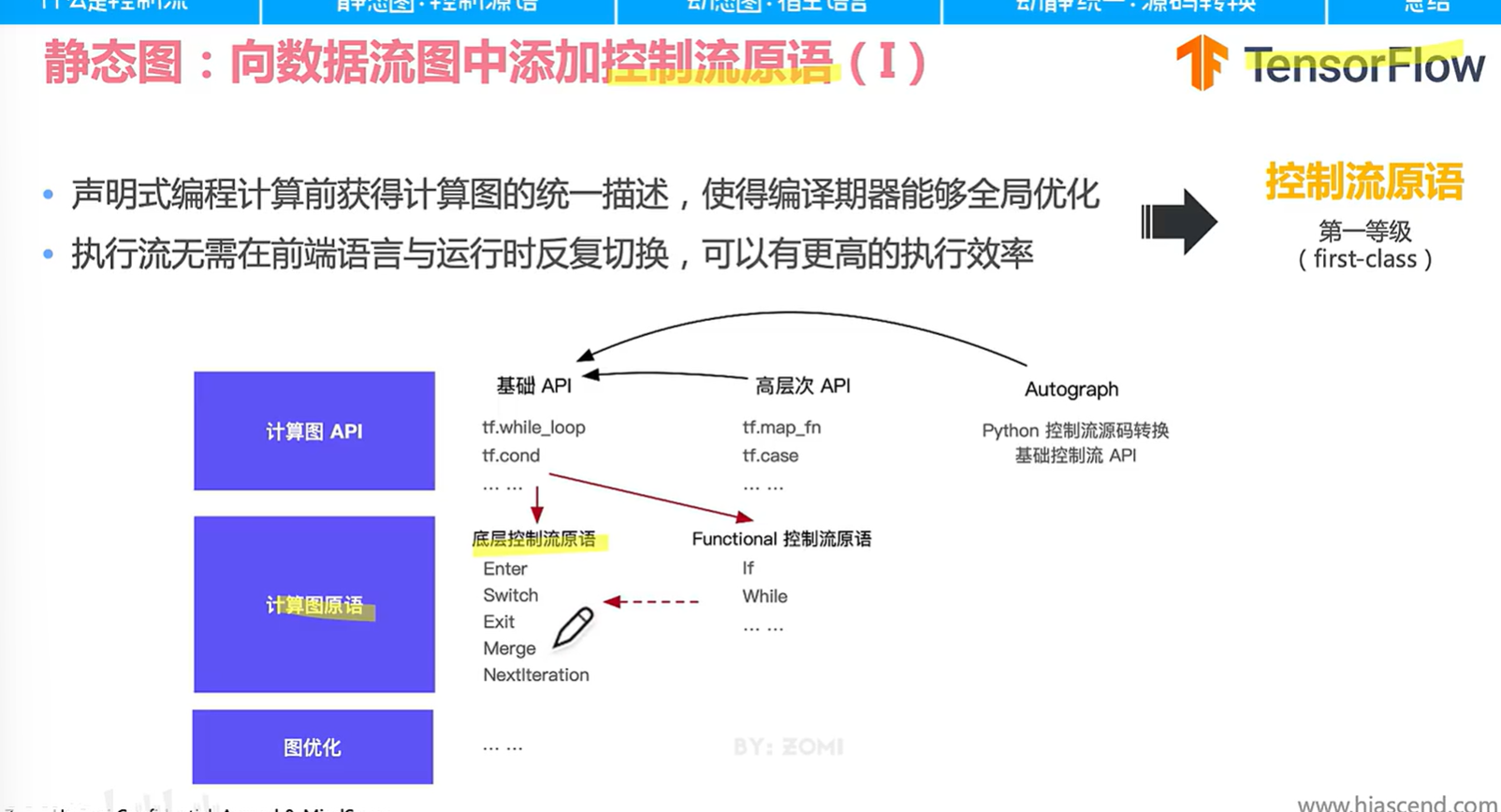
静态图的控制流原语就是下列图提到的 Enter等那五个,提前声明的好处是可以获得统一描述,不需要反复切换前端语言和运行时,都在runtime解决。
tf很麻烦要用到各种cond的基础api,虽然封装高层次api比如case之类的还是很难用;torch根据第三种源码转换的方式,可以把前端语句映射到对应的基础控制流api。
举个例子,一起看看tensorflow里面是怎么添加控制流原语的:

在tensorflow后面需要调用两个while loop进行嵌套表达。在底层的表达是有一个excution frame帧(里面是一个scope),里面保存了算子的上下文信息;嵌套for就使用了嵌套的执行帧。
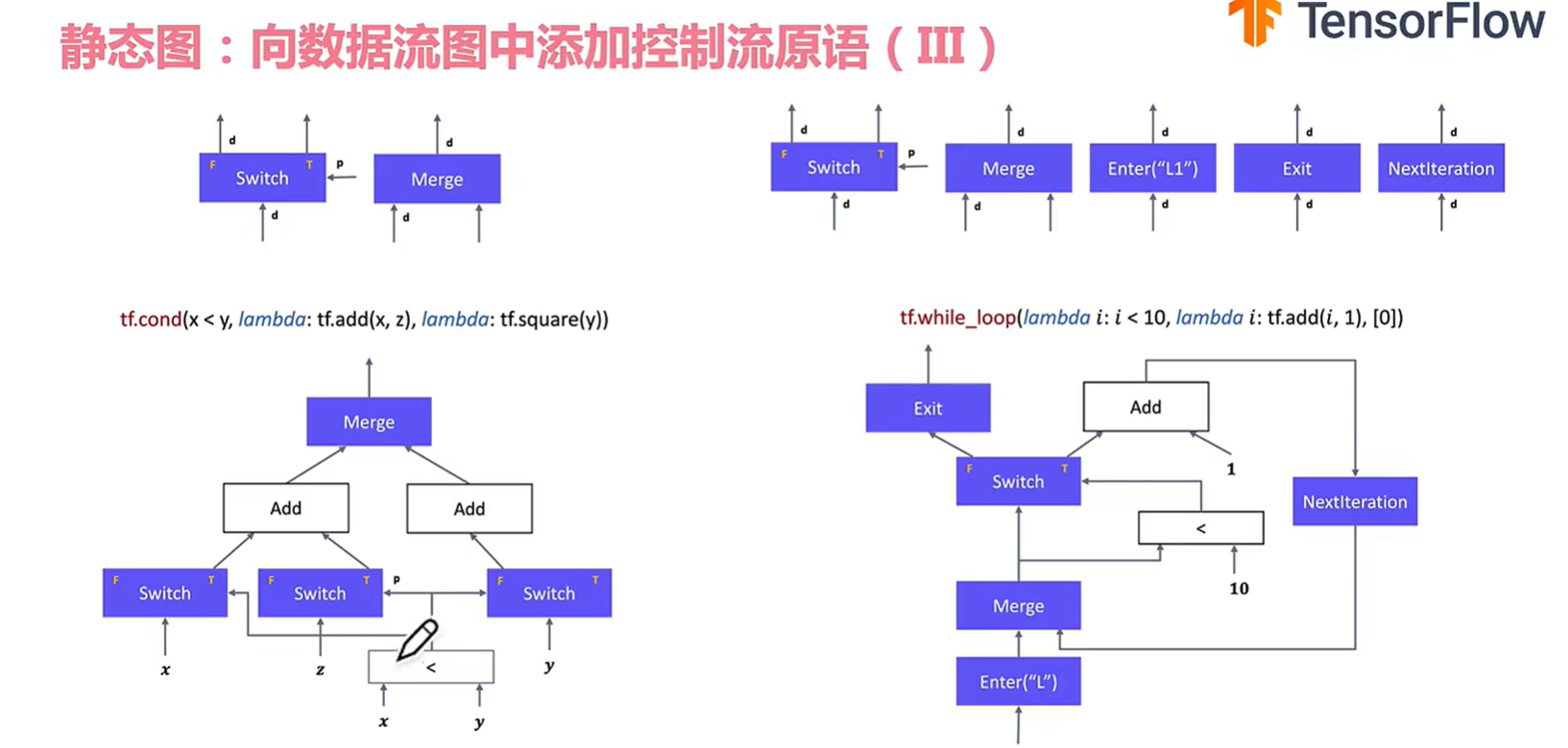
cond是用了 switch和merge原语组成的。实际上还是很难理解使用的…….
更复杂的操作就是while loop的操作(难怪tf越来越少人用。。)
接下来看看提供控制流原语的优缺点:(缺点太太太明显了。。需要花时间学习控制流到底是怎么表达和使用的,而且计算图被这么复杂化真的没法看了)

5.3 pytorch动态图控制流实现
对于torch而言,选择的是复用用户前端api语言控制流语句。
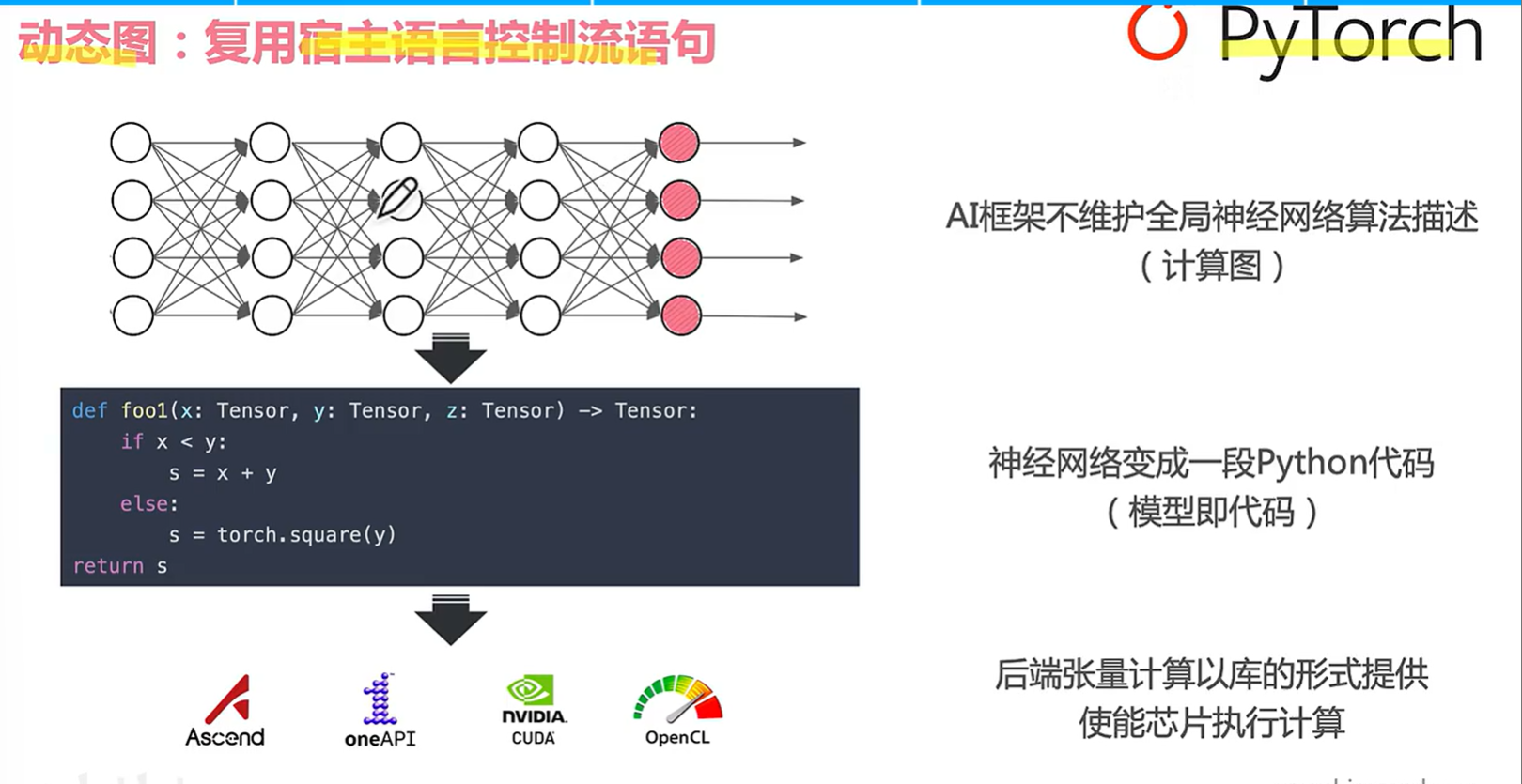
后端直接选择用库的行为执行算子,如果遇到控制流就在python里面执行。这个最大的好处就是可以灵活使用控制流而且马上输出张量的计算结果。缺点就是可能会带来性能问题,还有runtime开销。。。。无法进行全局计算图优化。
5.4 mindspore静态图控制流实现

接下来再看看mindspore的做法,源码解析展开和转换计算图。比如可以吧for变成串行的;if和else可以变成两个子图,运行时动态选择子图进行运算。这个好处是用户可以一定程度使用前端宿主控制流语言,同时也可以加速运行时效率,可以全局优化。
但是算子选择需要硬件支持。。。。部分python控制流代码也不能表示,有一定程度的约束性(并不是完成自由)
第六节 AI框架如何实现动静统一,torch和mindspore的动静统一现状
6.1动态图转换为静态图的方法
(paddle也有,然后mindspore说是第一次提出的)

接下来看看具体是怎么实现的 ,先看下trace

Trace的坏处是因为基于用户代码进行追踪,但这个覆盖率不一定全;所以遍历后变成静态图可能会造成图损失,实际上这个在实际框架比较少。。。。
以JIT(Just In Time)为例,其实是基于源代码解析。jit是运行时动态编译,在内存里生成和运行一段代码,一边编译一边执行。
基于源码解析的JIT方式如下:
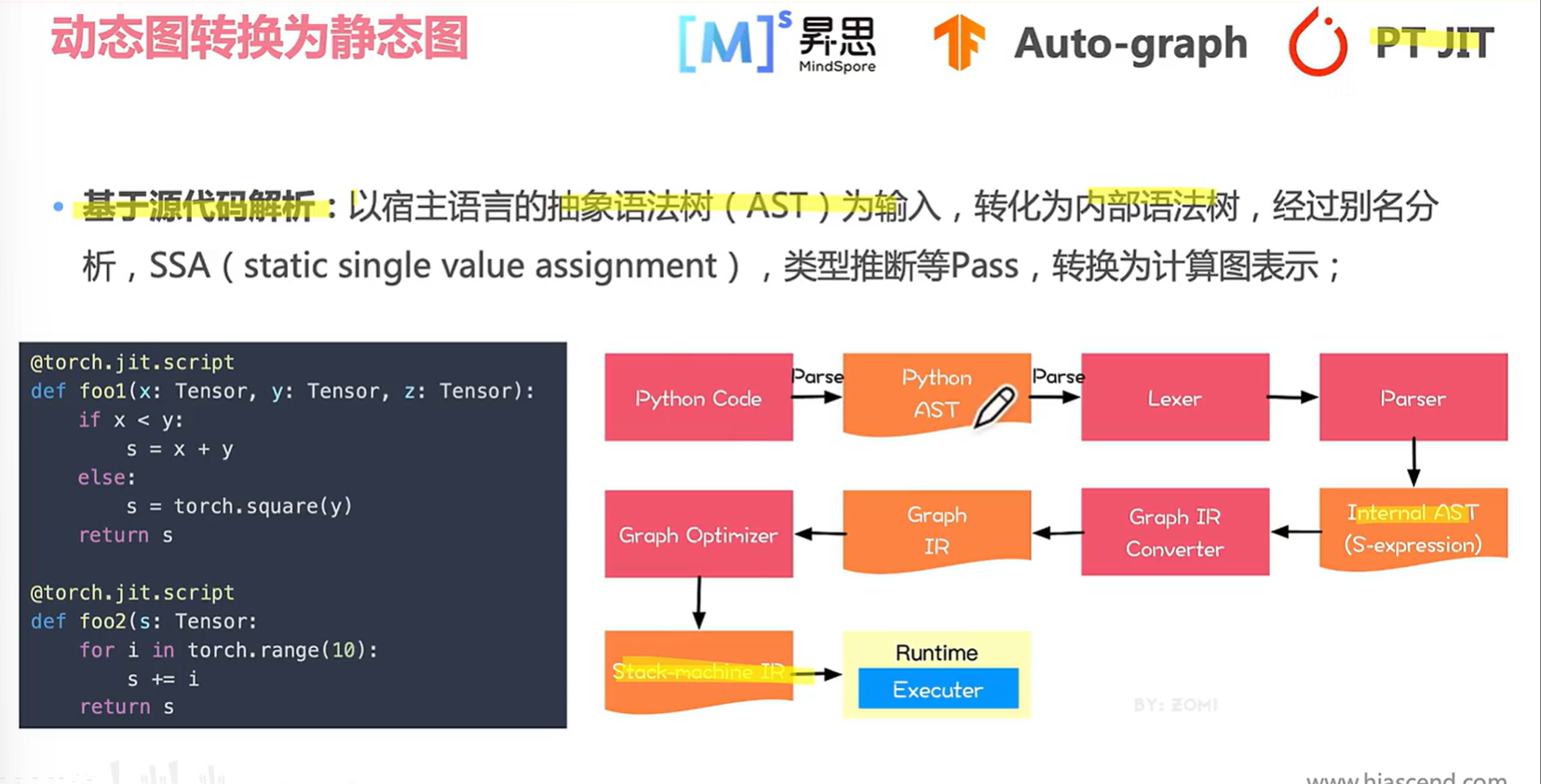


4 是一种对于123的解决方式。
第七节 计算图的挑战与未来
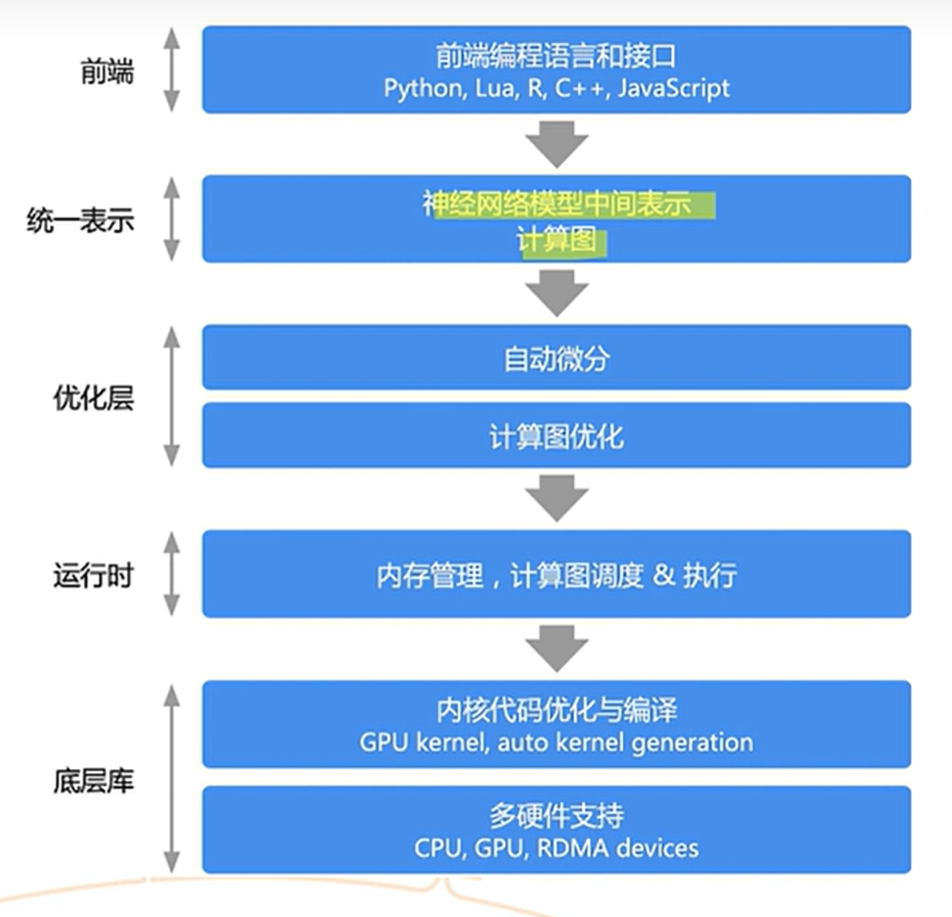
首先回顾一下计算图的基础数据结构:首先是用正向DAG构建反向DAG,计算图主要由节点和边构成的,所以可以叫做数据流图。计算图出现的好处是有了一个统一的表示,做到了分层解耦。
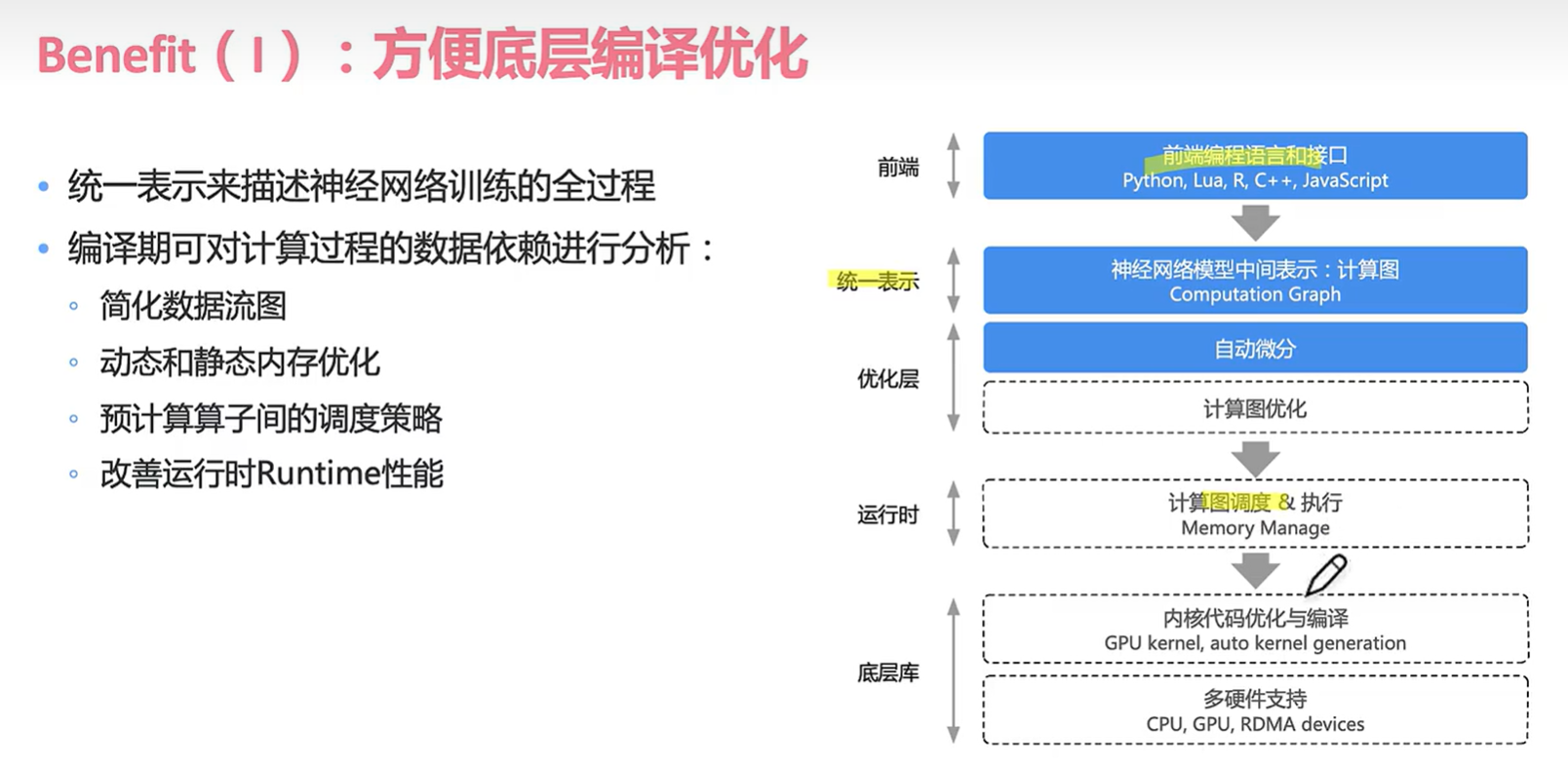
重要的就是三个优化层!
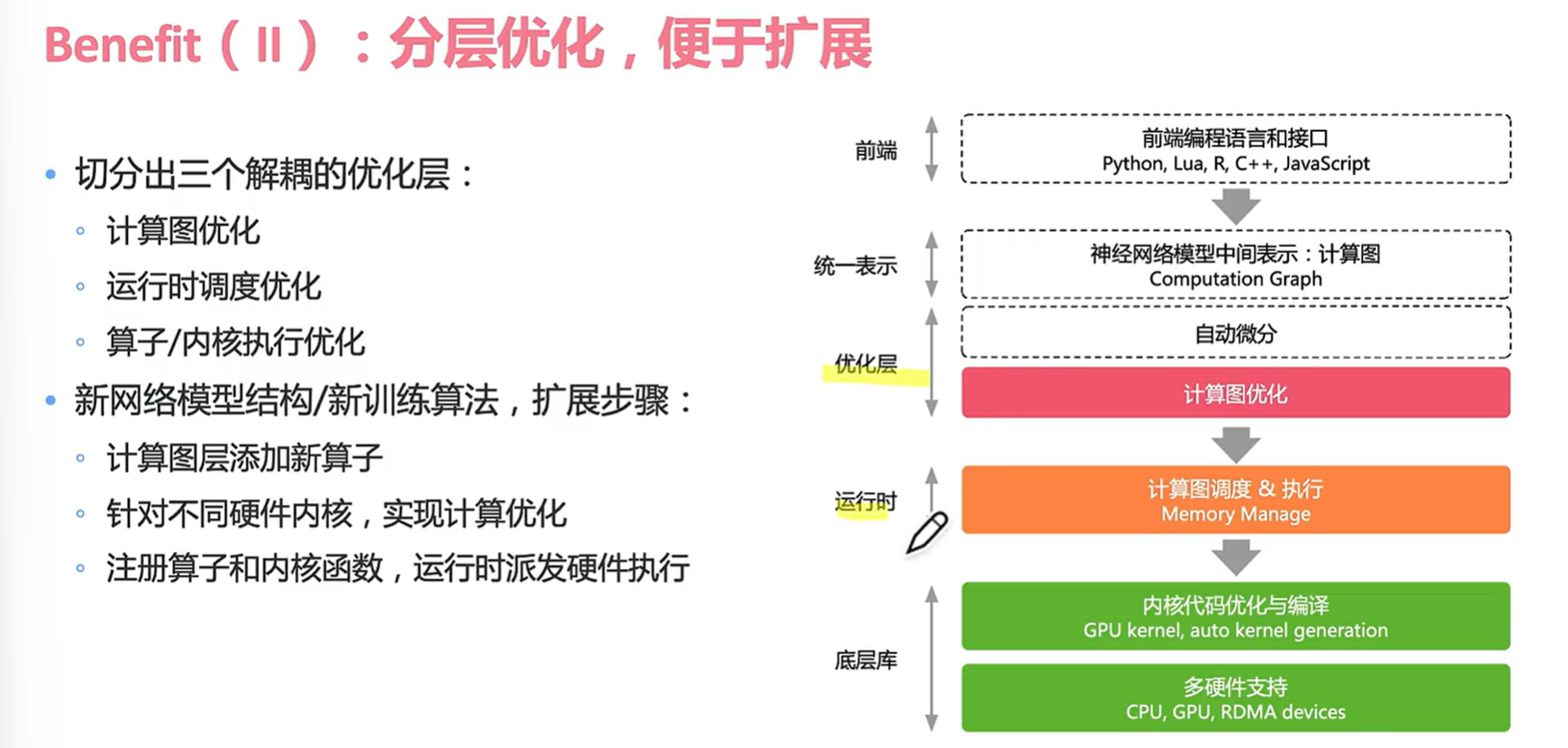
作者给出的思考:
一定需要明确的分层解耦?
pytorch没那么多层为什么这么成功?
新的diffusion和transform底层优化如何改变?
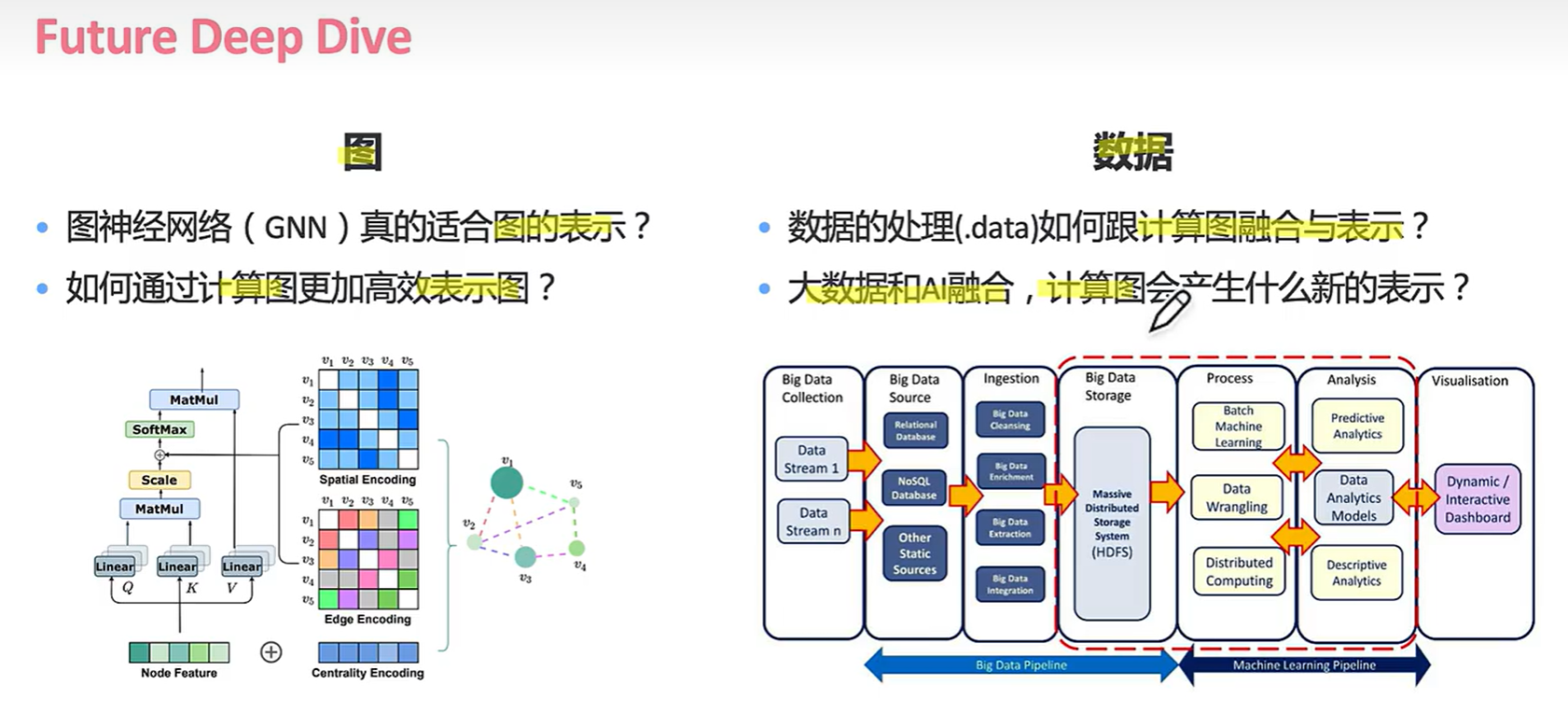
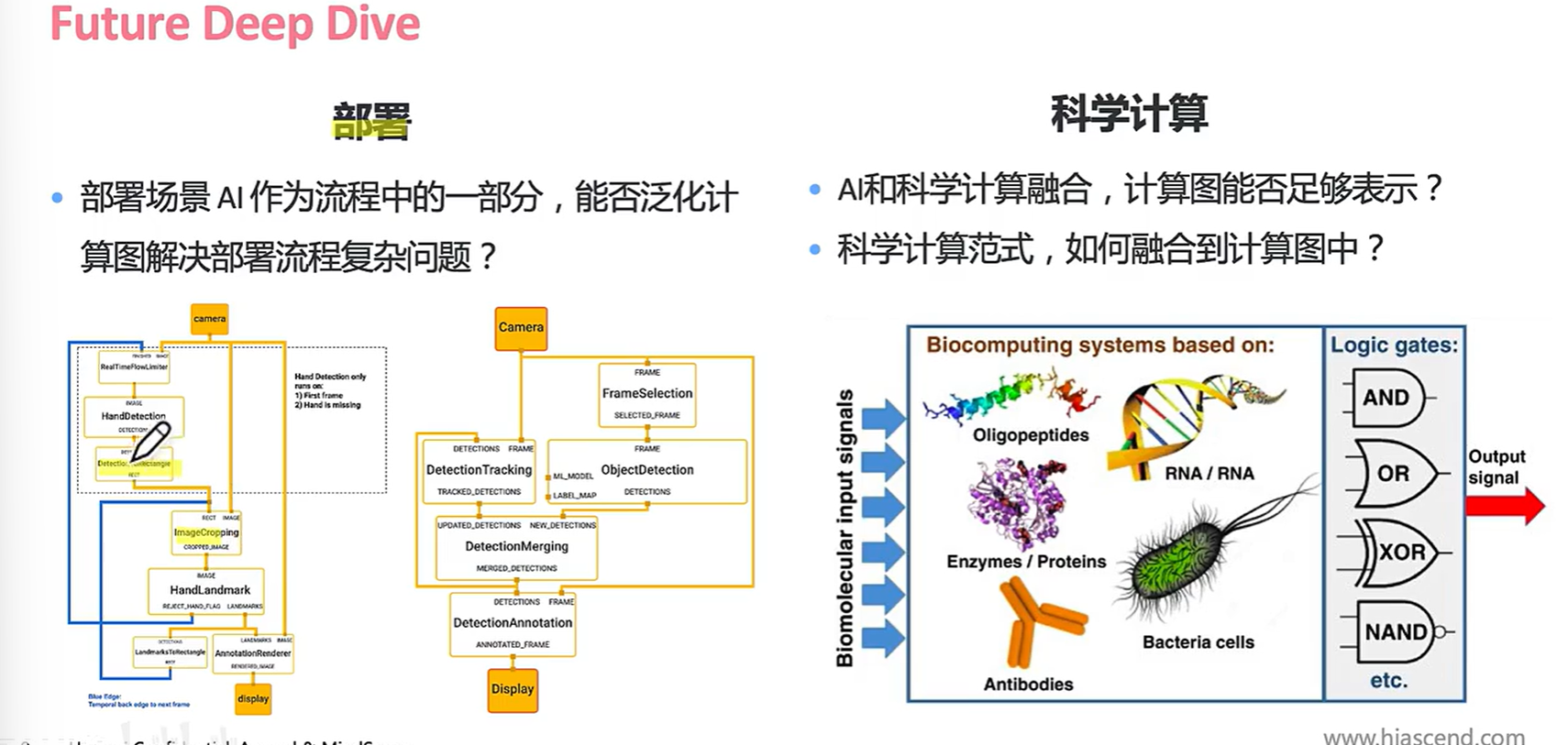
计算图不能解决AI 业务的哪些问题?
再来看更多: